 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Reinforcement Learning to Herd a Robotic Swarm to a Target Distribution
Jun 29, 2020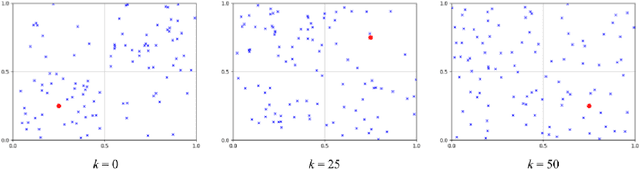

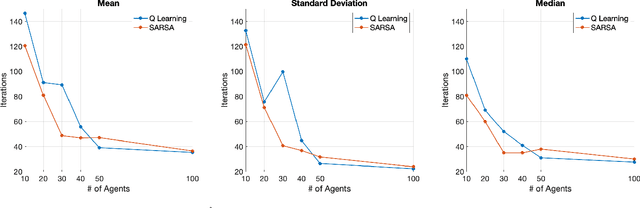
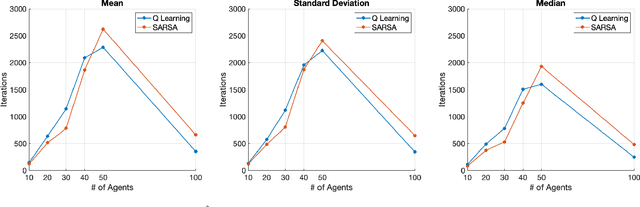
In this paper, we present a reinforcement learning approach to designing a control policy for a "leader'' agent that herds a swarm of "follower'' agents, via repulsive interactions, as quickly as possible to a target probability distribution over a strongly connected graph. The leader control policy is a function of the swarm distribution, which evolves over time according to a mean-field model in the form of an ordinary difference equation. The dependence of the policy on agent populations at each graph vertex, rather than on individual agent activity, simplifies the observations required by the leader and enables the control strategy to scale with the number of agents. Two Temporal-Difference learning algorithms, SARSA and Q-Learning, are used to generate the leader control policy based on the follower agent distribution and the leader's location on the graph. A simulation environment corresponding to a grid graph with 4 vertices was used to train and validate the control policies for follower agent populations ranging from 10 to 100. Finally, the control policies trained on 100 simulated agents were used to successfully redistribute a physical swarm of 10 small robots to a target distribution among 4 spatial regions.