 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJorge: Approximate Preconditioning for GPU-efficient Second-order Optimization
Oct 27, 2023


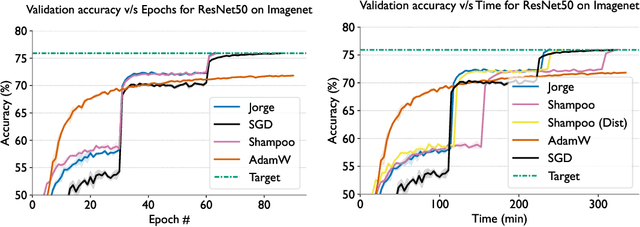
Despite their better convergence properties compared to first-order optimizers, second-order optimizers for deep learning have been less popular due to their significant computational costs. The primary efficiency bottleneck in such optimizers is matrix inverse calculations in the preconditioning step, which are expensive to compute on GPUs. In this paper, we introduce Jorge, a second-order optimizer that promises the best of both worlds -- rapid convergence benefits of second-order methods, and high computational efficiency typical of first-order methods. We address the primary computational bottleneck of computing matrix inverses by completely eliminating them using an approximation of the preconditioner computation. This makes Jorge extremely efficient on GPUs in terms of wall-clock time. Further, we describe an approach to determine Jorge's hyperparameters directly from a well-tuned SGD baseline, thereby significantly minimizing tuning efforts. Our empirical evaluations demonstrate the distinct advantages of using Jorge, outperforming state-of-the-art optimizers such as SGD, AdamW, and Shampoo across multiple deep learning models, both in terms of sample efficiency and wall-clock time.