 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalised OMP algorithm for feature selection with application to gene expression data
Apr 01, 2020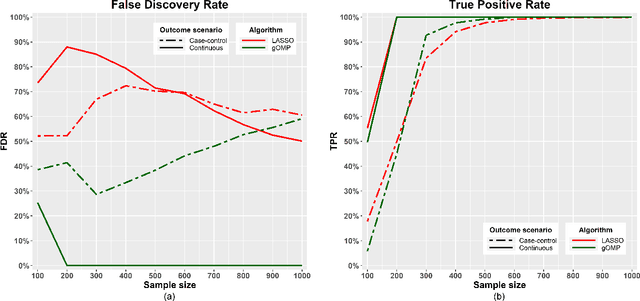
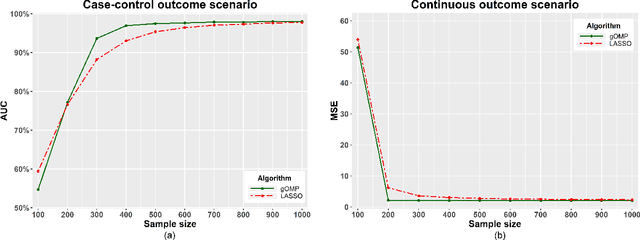
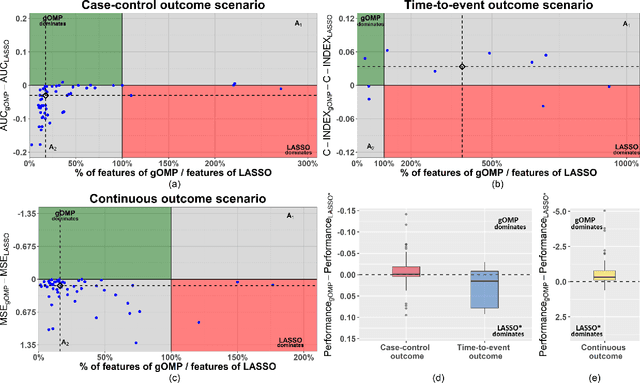
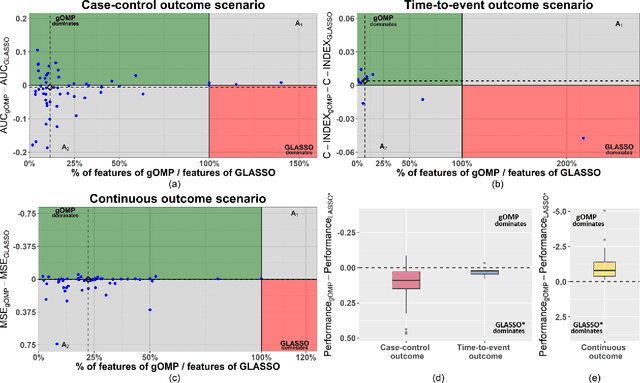
Feature selection for predictive analytics is the problem of identifying a minimal-size subset of features that is maximally predictive of an outcome of interest. To apply to molecular data, feature selection algorithms need to be scalable to tens of thousands of available features. In this paper, we propose gOMP, a highly-scalable generalisation of the Orthogonal Matching Pursuit feature selection algorithm to several directions: (a) different types of outcomes, such as continuous, binary, nominal, and time-to-event, (b) different types of predictive models (e.g., linear least squares, logistic regression), (c) different types of predictive features (continuous, categorical), and (d) different, statistical-based stopping criteria. We compare the proposed algorithm against LASSO, a prototypical, widely used algorithm for high-dimensional data. On dozens of simulated datasets, as well as, real gene expression datasets, gOMP is on par, or outperforms LASSO for case-control binary classification, quantified outcomes (regression), and (censored) survival times (time-to-event) analysis. gOMP has also several theoretical advantages that are discussed. While gOMP is based on quite simple and basic statistical ideas, easy to implement and to generalize, we also show in an extensive evaluation that it is also quite effective in bioinformatics analysis settings.