 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartitioning Distributed Compute Jobs with Reinforcement Learning and Graph Neural Networks
Jan 31, 2023From natural language processing to genome sequencing, large-scale machine learning models are bringing advances to a broad range of fields. Many of these models are too large to be trained on a single machine, and instead must be distributed across multiple devices. This has motivated the research of new compute and network systems capable of handling such tasks. In particular, recent work has focused on developing management schemes which decide how to allocate distributed resources such that some overall objective, such as minimising the job completion time (JCT), is optimised. However, such studies omit explicit consideration of how much a job should be distributed, usually assuming that maximum distribution is desirable. In this work, we show that maximum parallelisation is sub-optimal in relation to user-critical metrics such as throughput and blocking rate. To address this, we propose PAC-ML (partitioning for asynchronous computing with machine learning). PAC-ML leverages a graph neural network and reinforcement learning to learn how much to partition computation graphs such that the number of jobs which meet arbitrary user-defined JCT requirements is maximised. In experiments with five real deep learning computation graphs on a recently proposed optical architecture across four user-defined JCT requirement distributions, we demonstrate PAC-ML achieving up to 56.2% lower blocking rates in dynamic job arrival settings than the canonical maximum parallelisation strategy used by most prior works.
Network Aware Compute and Memory Allocation in Optically Composable Data Centres with Deep Reinforcement Learning and Graph Neural Networks
Oct 26, 2022



Resource-disaggregated data centre architectures promise a means of pooling resources remotely within data centres, allowing for both more flexibility and resource efficiency underlying the increasingly important infrastructure-as-a-service business. This can be accomplished by means of using an optically circuit switched backbone in the data centre network (DCN); providing the required bandwidth and latency guarantees to ensure reliable performance when applications are run across non-local resource pools. However, resource allocation in this scenario requires both server-level \emph{and} network-level resource to be co-allocated to requests. The online nature and underlying combinatorial complexity of this problem, alongside the typical scale of DCN topologies, makes exact solutions impossible and heuristic based solutions sub-optimal or non-intuitive to design. We demonstrate that \emph{deep reinforcement learning}, where the policy is modelled by a \emph{graph neural network} can be used to learn effective \emph{network-aware} and \emph{topologically-scalable} allocation policies end-to-end. Compared to state-of-the-art heuristics for network-aware resource allocation, the method achieves up to $20\%$ higher acceptance ratio; can achieve the same acceptance ratio as the best performing heuristic with $3\times$ less networking resources available and can maintain all-around performance when directly applied (with no further training) to DCN topologies with $10^2\times$ more servers than the topologies seen during training.
One-shot, Offline and Production-Scalable PID Optimisation with Deep Reinforcement Learning
Oct 25, 2022



Proportional-integral-derivative (PID) control underlies more than $97\%$ of automated industrial processes. Controlling these processes effectively with respect to some specified set of performance goals requires finding an optimal set of PID parameters to moderate the PID loop. Tuning these parameters is a long and exhaustive process. A method (patent pending) based on deep reinforcement learning is presented that learns a relationship between generic system properties (e.g. resonance frequency), a multi-objective performance goal and optimal PID parameter values. Performance is demonstrated in the context of a real optical switching product of the foremost manufacturer of such devices globally. Switching is handled by piezoelectric actuators where switching time and optical loss are derived from the speed and stability of actuator-control processes respectively. The method achieves a $5\times$ improvement in the number of actuators that fall within the most challenging target switching speed, $\geq 20\%$ improvement in mean switching speed at the same optical loss and $\geq 75\%$ reduction in performance inconsistency when temperature varies between 5 and 73 degrees celcius. Furthermore, once trained (which takes $\mathcal{O}(hours)$), the model generates actuator-unique PID parameters in a one-shot inference process that takes $\mathcal{O}(ms)$ in comparison to up to $\mathcal{O}(week)$ required for conventional tuning methods, therefore accomplishing these performance improvements whilst achieving up to a $10^6\times$ speed-up. After training, the method can be applied entirely offline, incurring effectively zero optimisation-overhead in production.
Nara: Learning Network-Aware Resource Allocation Algorithms for Cloud Data Centres
Jun 04, 2021


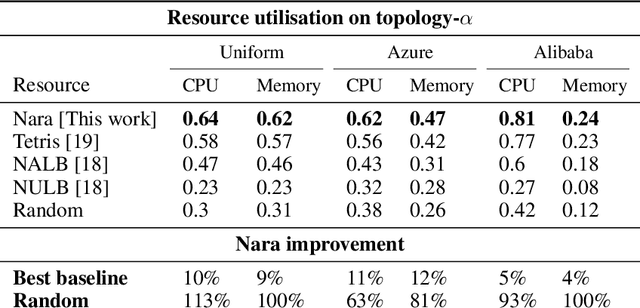
Data centres (DCs) underline many prominent future technological trends such as distributed training of large scale machine learning models and internet-of-things based platforms. DCs will soon account for over 3\% of global energy demand, so efficient use of DC resources is essential. Robust DC networks (DCNs) are essential to form the large scale systems needed to handle this demand, but can bottleneck how efficiently DC-server resources can be used when servers with insufficient connectivity between them cannot be jointly allocated to a job. However, allocating servers' resources whilst accounting for their inter-connectivity maps to an NP-hard combinatorial optimisation problem, and so is often ignored in DC resource management schemes. We present Nara, a framework based on reinforcement learning (RL) and graph neural networks (GNN) to learn network-aware allocation policies that increase the number of requests allocated over time compared to previous methods. Unique to our solution is the use of a GNN to generate representations of server-nodes in the DCN, which are then interpreted as actions by a RL policy-network which chooses from which servers resources will be allocated to incoming requests. Nara is agnostic to the topology size and shape and is trained end-to-end. The method can accept up to 33\% more requests than the best baseline when deployed on DCNs with up to the order of $10\times$ more compute nodes than the DCN seen during training and is able to maintain its policy's performance on DCNs with the order of $100\times$ more servers than seen during training. It also generalises to unseen DCN topologies with varied network structure and unseen request distributions without re-training.