Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Algorithm Matters for the Performance of Neural Network Potential
Sep 08, 2021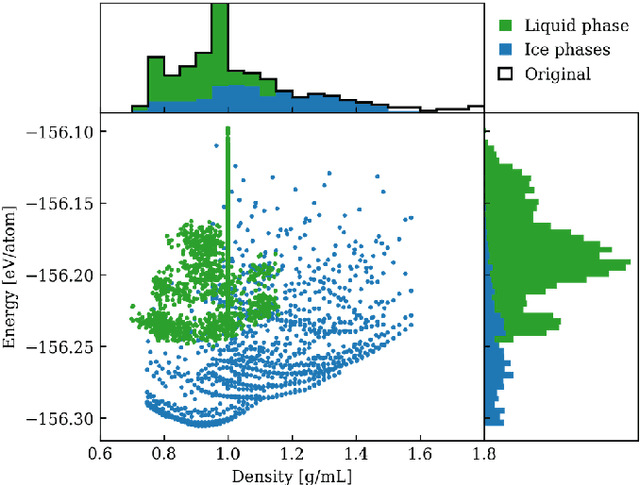
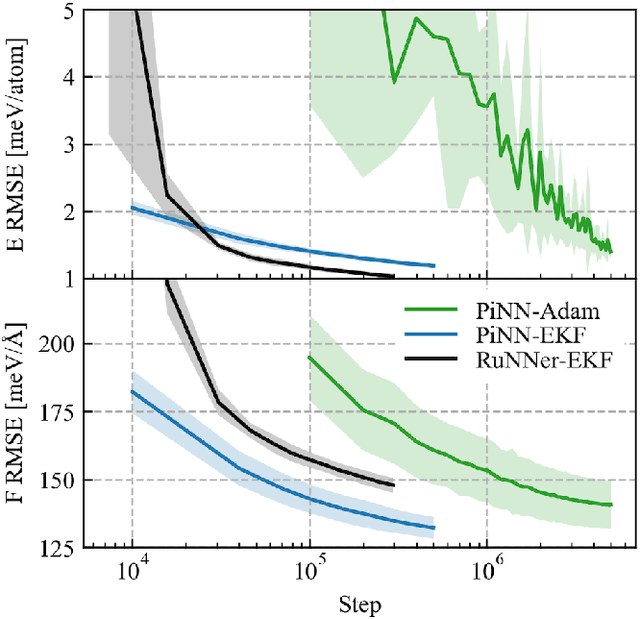
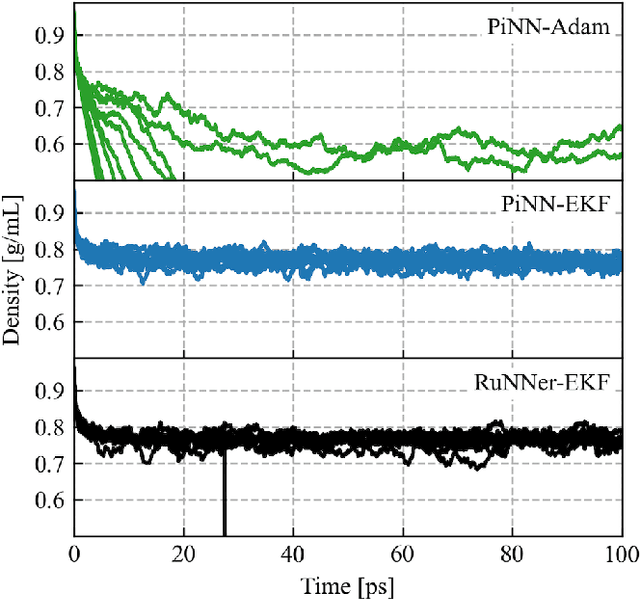
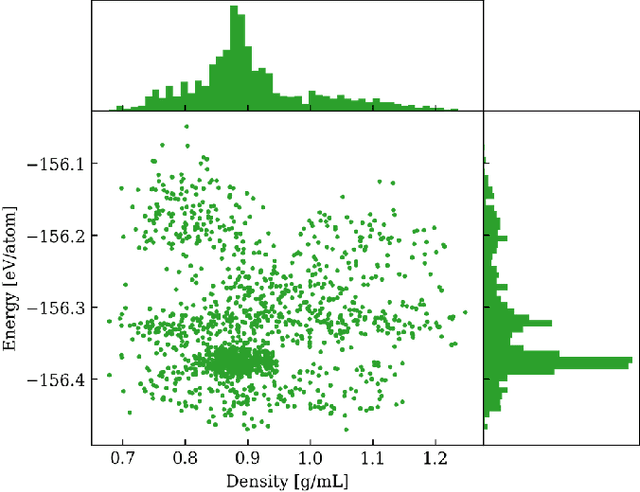
One hidden yet important issue for developing neural network potentials (NNPs) is the choice of training algorithm. Here we compare the performance of two popular training algorithms, the adaptive moment estimation algorithm (Adam) and the extended Kalman filter algorithm (EKF), using the Behler-Parrinello neural network (BPNN) and two publicly accessible datasets of liquid water. It is found that NNPs trained with EKF are more transferable and less sensitive to the value of the learning rate, as compared to Adam. In both cases, error metrics of the test set do not always serve as a good indicator for the actual performance of NNPs. Instead, we show that their performance correlates well with a Fisher information based similarity measure.
Via