 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPoRC-VIST: A Benchmark for Evaluating Generative Natural Narrative in Vision-Language Models
Jan 03, 2026Vision-Language Models (VLMs) have achieved remarkable success in descriptive tasks such as image captioning and visual question answering (VQA). However, their ability to generate engaging, long-form narratives -- specifically multi-speaker podcast dialogues -- remains under-explored and difficult to evaluate. Standard metrics like BLEU and ROUGE fail to capture the nuances of conversational naturalness, personality, and narrative flow, often rewarding safe, repetitive outputs over engaging storytelling. In this work, we present a novel pipeline for end-to-end visual podcast generation, and fine-tune a Qwen3-VL-32B model on a curated dataset of 4,000 image-dialogue pairs. Crucially, we use a synthetic-to-real training strategy: we train on high-quality podcast dialogues from the Structured Podcast Research Corpus (SPoRC) paired with synthetically generated imagery, and evaluate on real-world photo sequences from the Visual Storytelling Dataset (VIST). This rigorous setup tests the model's ability to generalize from synthetic training data to real-world visual domains. We propose a comprehensive evaluation framework that moves beyond textual overlap, and use AI-as-a-judge (Gemini 3 Pro, Claude Opus 4.5, GPT 5.2) and novel style metrics (average turn length, speaker switch rate) to assess quality. Our experiments demonstrate that our fine-tuned 32B model significantly outperforms a 235B base model in conversational naturalness ($>$80\% win rate) and narrative depth (+50\% turn length), while maintaining identical visual grounding capabilities (CLIPScore: 20.39).
Power-scaled Bayesian Inference with Score-based Generative mModels
Apr 15, 2025We propose a score-based generative algorithm for sampling from power-scaled priors and likelihoods within the Bayesian inference framework. Our algorithm enables flexible control over prior-likelihood influence without requiring retraining for different power-scaling configurations. Specifically, we focus on synthesizing seismic velocity models conditioned on imaged seismic. Our method enables sensitivity analysis by sampling from intermediate power posteriors, allowing us to assess the relative influence of the prior and likelihood on samples of the posterior distribution. Through a comprehensive set of experiments, we evaluate the effects of varying the power parameter in different settings: applying it solely to the prior, to the likelihood of a Bayesian formulation, and to both simultaneously. The results show that increasing the power of the likelihood up to a certain threshold improves the fidelity of posterior samples to the conditioning data (e.g., seismic images), while decreasing the prior power promotes greater structural diversity among samples. Moreover, we find that moderate scaling of the likelihood leads to a reduced shot data residual, confirming its utility in posterior refinement.
Machine learning-enabled velocity model building with uncertainty quantification
Nov 14, 2024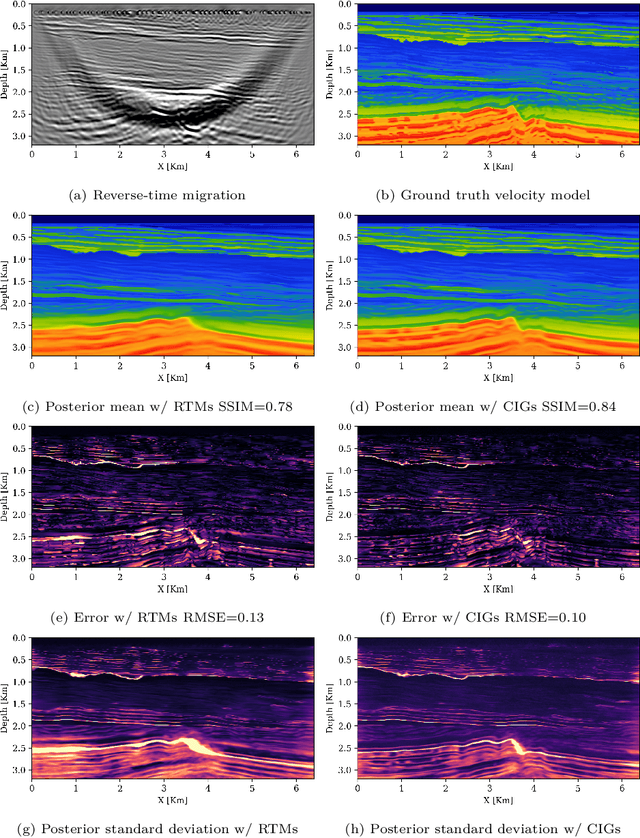
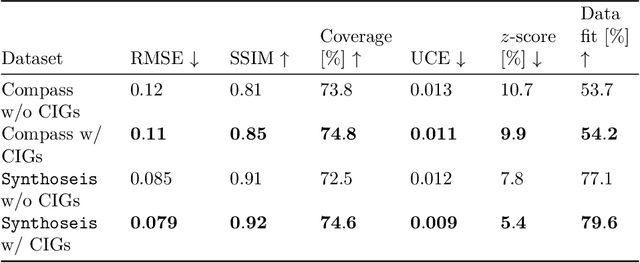
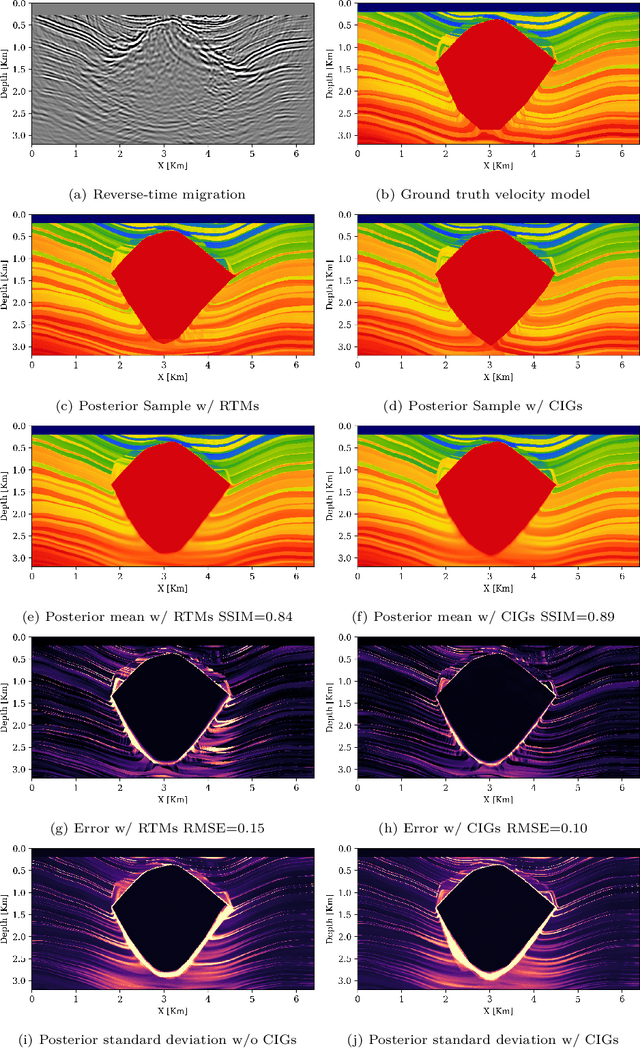

Accurately characterizing migration velocity models is crucial for a wide range of geophysical applications, from hydrocarbon exploration to monitoring of CO2 sequestration projects. Traditional velocity model building methods such as Full-Waveform Inversion (FWI) are powerful but often struggle with the inherent complexities of the inverse problem, including noise, limited bandwidth, receiver aperture and computational constraints. To address these challenges, we propose a scalable methodology that integrates generative modeling, in the form of Diffusion networks, with physics-informed summary statistics, making it suitable for complicated imaging problems including field datasets. By defining these summary statistics in terms of subsurface-offset image volumes for poor initial velocity models, our approach allows for computationally efficient generation of Bayesian posterior samples for migration velocity models that offer a useful assessment of uncertainty. To validate our approach, we introduce a battery of tests that measure the quality of the inferred velocity models, as well as the quality of the inferred uncertainties. With modern synthetic datasets, we reconfirm gains from using subsurface-image gathers as the conditioning observable. For complex velocity model building involving salt, we propose a new iterative workflow that refines amortized posterior approximations with salt flooding and demonstrate how the uncertainty in the velocity model can be propagated to the final product reverse time migrated images. Finally, we present a proof of concept on field datasets to show that our method can scale to industry-sized problems.