 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Classification by Physics-informed Inpainting for Distributed Multichannel Acoustic Sensor with Partially Degraded Channels
Jan 20, 2026Distributed multichannel acoustic sensing (DMAS) enables large-scale sound event classification (SEC), but performance drops when many channels are degraded and when sensor layouts at test time differ from training layouts. We propose a learning-free, physics-informed inpainting frontend based on reverse time migration (RTM). In this approach, observed multichannel spectrograms are first back-propagated on a 3D grid using an analytic Green's function to form a scene-consistent image, and then forward-projected to reconstruct inpainted signals before log-mel feature extraction and Transformer-based classification. We evaluate the method on ESC-50 with 50 sensors and three layouts (circular, linear, right-angle), where per-channel SNRs are sampled from -30 to 0 dB. Compared with an AST baseline, scaling-sparsemax channel selection, and channel-swap augmentation, the proposed RTM frontend achieves the best or competitive accuracy across all layouts, improving accuracy by 13.1 points on the right-angle layout (from 9.7% to 22.8%). Correlation analyses show that spatial weights align more strongly with SNR than with channel--source distance, and that higher SNR--weight correlation corresponds to higher SEC accuracy. These results demonstrate that a reconstruct-then-project, physics-based preprocessing effectively complements learning-only methods for DMAS under layout-open configurations and severe channel degradation.
Low-rank constrained multichannel signal denoising considering channel-dependent sensitivity inspired by self-supervised learning for optical fiber sensing
Dec 16, 2023Optical fiber sensing is a technology wherein audio, vibrations, and temperature are detected using an optical fiber; especially the audio/vibrations-aware sensing is called distributed acoustic sensing (DAS). In DAS, observed data, which is comprised of multichannel data, has suffered from severe noise levels because of the optical noise or the installation methods. In conventional methods for denoising DAS data, signal-processing- or deep-neural-network (DNN)-based models have been studied. The signal-processing-based methods have the interpretability, i.e., non-black box. The DNN-based methods are good at flexibility designing network architectures and objective functions, that is, priors. However, there is no balance between the interpretability and the flexibility of priors in the DAS studies. The DNN-based methods also require a large amount of training data in general. To address the problems, we propose a DNN-structure signal-processing-based denoising method in this paper. As the priors of DAS, we employ spatial knowledge; low rank and channel-dependent sensitivity using the DNN-based structure. The result of fiber-acoustic sensing shows that the proposed method outperforms the conventional methods and the robustness to the number of the spatial ranks. Moreover, the optimized parameters of the proposed method indicate the relationship with the channel sensitivity; the interpretability.
Impact of Sound Duration and Inactive Frames on Sound Event Detection Performance
Feb 03, 2021
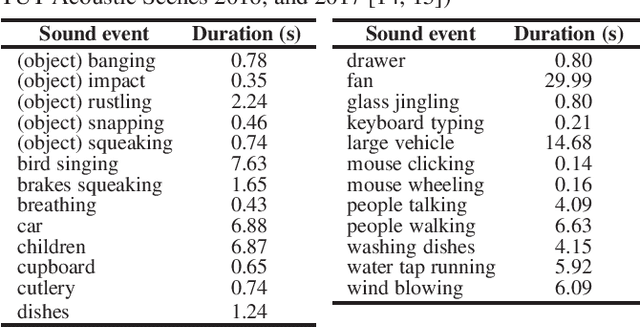
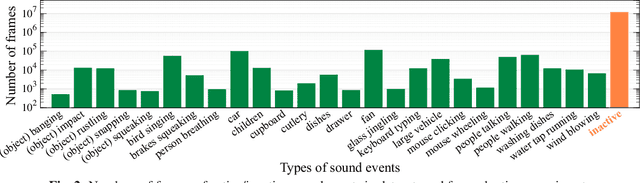

In many methods of sound event detection (SED), a segmented time frame is regarded as one data sample to model training. The durations of sound events greatly depend on the sound event class, e.g., the sound event "fan" has a long duration, whereas the sound event "mouse clicking" is instantaneous. Thus, the difference in the duration between sound event classes results in a serious data imbalance in SED. Moreover, most sound events tend to occur occasionally; therefore, there are many more inactive time frames of sound events than active frames. This also causes a severe data imbalance between active and inactive frames. In this paper, we investigate the impact of sound duration and inactive frames on SED performance by introducing four loss functions, such as simple reweighting loss, inverse frequency loss, asymmetric focal loss, and focal batch Tversky loss. Then, we provide insights into how we tackle this imbalance problem.