 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToy-GS: Assembling Local Gaussians for Precisely Rendering Large-Scale Free Camera Trajectories
Dec 13, 2024

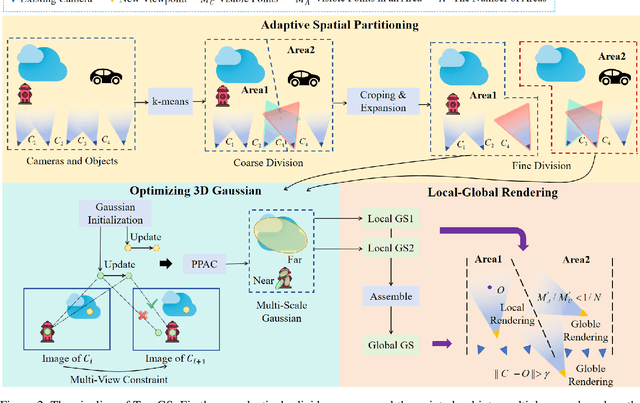
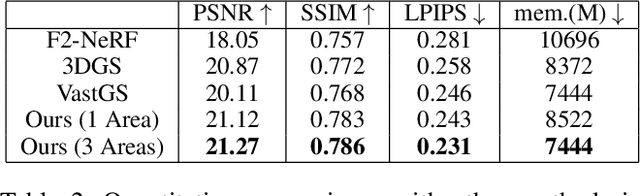
Currently, 3D rendering for large-scale free camera trajectories, namely, arbitrary input camera trajectories, poses significant challenges: 1) The distribution and observation angles of the cameras are irregular, and various types of scenes are included in the free trajectories; 2) Processing the entire point cloud and all images at once for large-scale scenes requires a substantial amount of GPU memory. This paper presents a Toy-GS method for accurately rendering large-scale free camera trajectories. Specifically, we propose an adaptive spatial division approach for free trajectories to divide cameras and the sparse point cloud of the entire scene into various regions according to camera poses. Training each local Gaussian in parallel for each area enables us to concentrate on texture details and minimize GPU memory usage. Next, we use the multi-view constraint and position-aware point adaptive control (PPAC) to improve the rendering quality of texture details. In addition, our regional fusion approach combines local and global Gaussians to enhance rendering quality with an increasing number of divided areas. Extensive experiments have been carried out to confirm the effectiveness and efficiency of Toy-GS, leading to state-of-the-art results on two public large-scale datasets as well as our SCUTic dataset. Our proposal demonstrates an enhancement of 1.19 dB in PSNR and conserves 7 G of GPU memory when compared to various benchmarks.
Aerial-NeRF: Adaptive Spatial Partitioning and Sampling for Large-Scale Aerial Rendering
May 10, 2024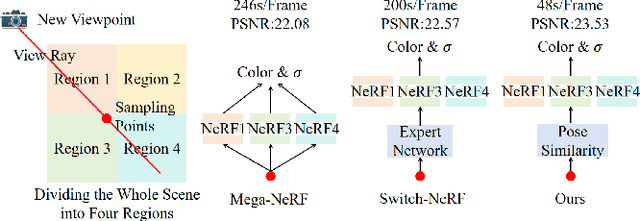
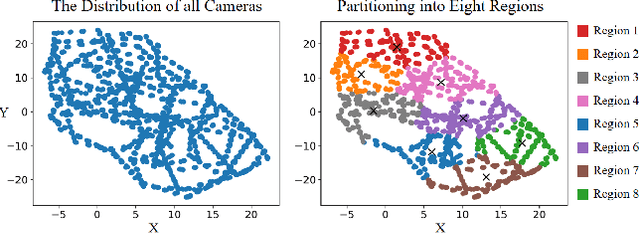


Recent progress in large-scale scene rendering has yielded Neural Radiance Fields (NeRF)-based models with an impressive ability to synthesize scenes across small objects and indoor scenes. Nevertheless, extending this idea to large-scale aerial rendering poses two critical problems. Firstly, a single NeRF cannot render the entire scene with high-precision for complex large-scale aerial datasets since the sampling range along each view ray is insufficient to cover buildings adequately. Secondly, traditional NeRFs are infeasible to train on one GPU to enable interactive fly-throughs for modeling massive images. Instead, existing methods typically separate the whole scene into multiple regions and train a NeRF on each region, which are unaccustomed to different flight trajectories and difficult to achieve fast rendering. To that end, we propose Aerial-NeRF with three innovative modifications for jointly adapting NeRF in large-scale aerial rendering: (1) Designing an adaptive spatial partitioning and selection method based on drones' poses to adapt different flight trajectories; (2) Using similarity of poses instead of (expert) network for rendering speedup to determine which region a new viewpoint belongs to; (3) Developing an adaptive sampling approach for rendering performance improvement to cover the entire buildings at different heights. Extensive experiments have conducted to verify the effectiveness and efficiency of Aerial-NeRF, and new state-of-the-art results have been achieved on two public large-scale aerial datasets and presented SCUTic dataset. Note that our model allows us to perform rendering over 4 times as fast as compared to multiple competitors. Our dataset, code, and model are publicly available at https://drliuqi.github.io/.