 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Emotion Recognition with Co-Attention based Multi-level Acoustic Information
Mar 29, 2022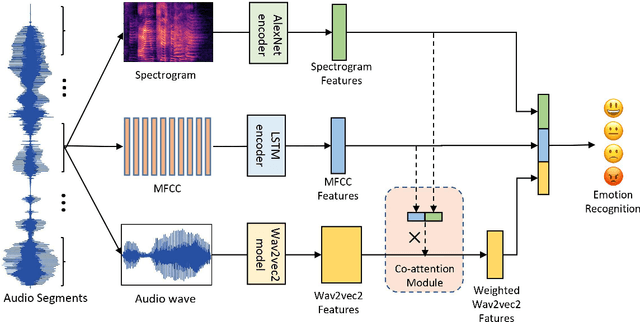
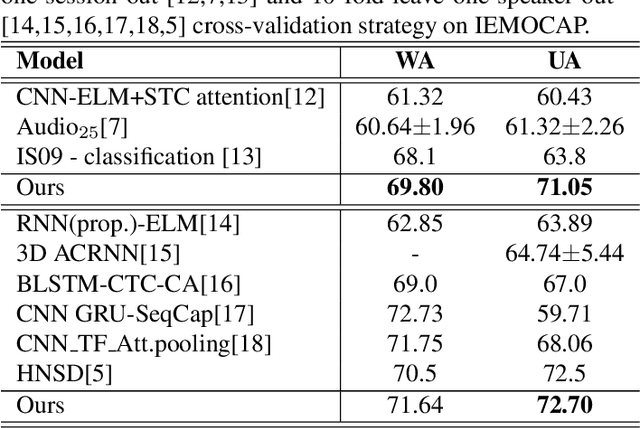
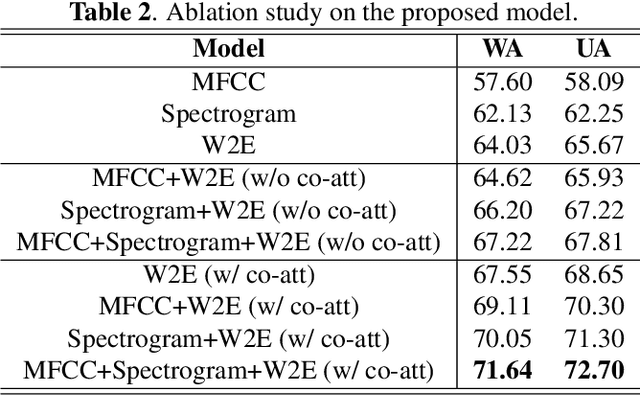
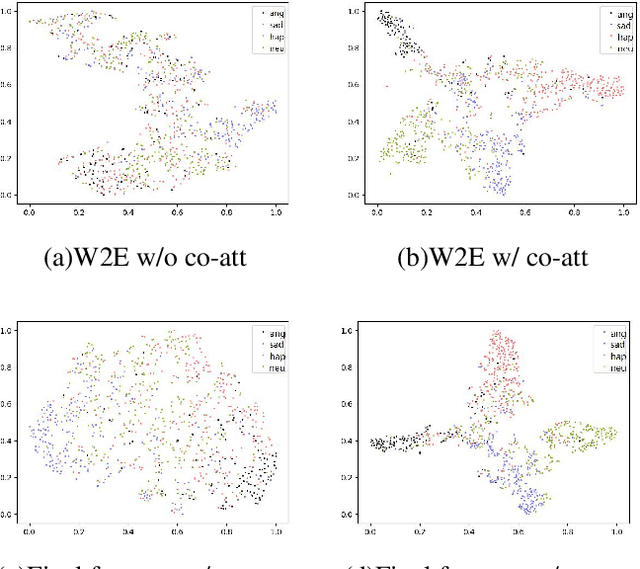
Speech Emotion Recognition (SER) aims to help the machine to understand human's subjective emotion from only audio information. However, extracting and utilizing comprehensive in-depth audio information is still a challenging task. In this paper, we propose an end-to-end speech emotion recognition system using multi-level acoustic information with a newly designed co-attention module. We firstly extract multi-level acoustic information, including MFCC, spectrogram, and the embedded high-level acoustic information with CNN, BiLSTM and wav2vec2, respectively. Then these extracted features are treated as multimodal inputs and fused by the proposed co-attention mechanism. Experiments are carried on the IEMOCAP dataset, and our model achieves competitive performance with two different speaker-independent cross-validation strategies. Our code is available on GitHub.