 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Object Detection in RGB-D Videos
Oct 24, 2023



Given the widespread adoption of depth-sensing acquisition devices, RGB-D videos and related data/media have gained considerable traction in various aspects of daily life. Consequently, conducting salient object detection (SOD) in RGB-D videos presents a highly promising and evolving avenue. Despite the potential of this area, SOD in RGB-D videos remains somewhat under-explored, with RGB-D SOD and video SOD (VSOD) traditionally studied in isolation. To explore this emerging field, this paper makes two primary contributions: the dataset and the model. On one front, we construct the RDVS dataset, a new RGB-D VSOD dataset with realistic depth and characterized by its diversity of scenes and rigorous frame-by-frame annotations. We validate the dataset through comprehensive attribute and object-oriented analyses, and provide training and testing splits. Moreover, we introduce DCTNet+, a three-stream network tailored for RGB-D VSOD, with an emphasis on RGB modality and treats depth and optical flow as auxiliary modalities. In pursuit of effective feature enhancement, refinement, and fusion for precise final prediction, we propose two modules: the multi-modal attention module (MAM) and the refinement fusion module (RFM). To enhance interaction and fusion within RFM, we design a universal interaction module (UIM) and then integrate holistic multi-modal attentive paths (HMAPs) for refining multi-modal low-level features before reaching RFMs. Comprehensive experiments, conducted on pseudo RGB-D video datasets alongside our RDVS, highlight the superiority of DCTNet+ over 17 VSOD models and 14 RGB-D SOD models. Ablation experiments were performed on both pseudo and realistic RGB-D video datasets to demonstrate the advantages of individual modules as well as the necessity of introducing realistic depth. Our code together with RDVS dataset will be available at https://github.com/kerenfu/RDVS/.
Depth-Cooperated Trimodal Network for Video Salient Object Detection
Feb 12, 2022
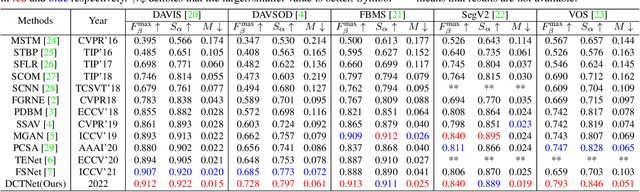
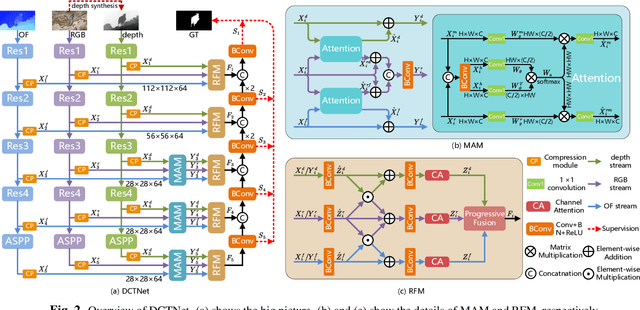
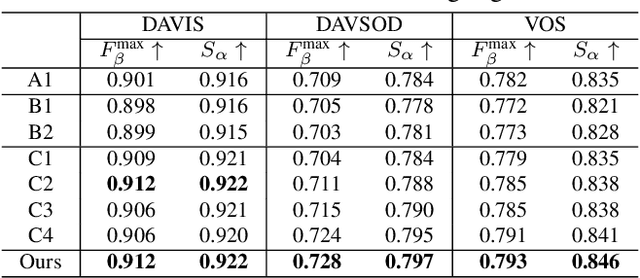
Depth can provide useful geographical cues for salient object detection (SOD), and has been proven helpful in recent RGB-D SOD methods. However, existing video salient object detection (VSOD) methods only utilize spatiotemporal information and seldom exploit depth information for detection. In this paper, we propose a depth-cooperated trimodal network, called DCTNet for VSOD, which is a pioneering work to incorporate depth information to assist VSOD. To this end, we first generate depth from RGB frames, and then propose an approach to treat the three modalities unequally. Specifically, a multi-modal attention module (MAM) is designed to model multi-modal long-range dependencies between the main modality (RGB) and the two auxiliary modalities (depth, optical flow). We also introduce a refinement fusion module (RFM) to suppress noises in each modality and select useful information dynamically for further feature refinement. Lastly, a progressive fusion strategy is adopted after the refined features to achieve final cross-modal fusion. Experiments on five benchmark datasets demonstrate the superiority of our depth-cooperated model against 12 state-of-the-art methods, and the necessity of depth is also validated.