 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Wise Perturbations via Sparse Autoencoders for Adversarial Text Generation
Aug 14, 2025With the rapid proliferation of Natural Language Processing (NLP), especially Large Language Models (LLMs), generating adversarial examples to jailbreak LLMs remains a key challenge for understanding model vulnerabilities and improving robustness. In this context, we propose a new black-box attack method that leverages the interpretability of large models. We introduce the Sparse Feature Perturbation Framework (SFPF), a novel approach for adversarial text generation that utilizes sparse autoencoders to identify and manipulate critical features in text. After using the SAE model to reconstruct hidden layer representations, we perform feature clustering on the successfully attacked texts to identify features with higher activations. These highly activated features are then perturbed to generate new adversarial texts. This selective perturbation preserves the malicious intent while amplifying safety signals, thereby increasing their potential to evade existing defenses. Our method enables a new red-teaming strategy that balances adversarial effectiveness with safety alignment. Experimental results demonstrate that adversarial texts generated by SFPF can bypass state-of-the-art defense mechanisms, revealing persistent vulnerabilities in current NLP systems.However, the method's effectiveness varies across prompts and layers, and its generalizability to other architectures and larger models remains to be validated.
Targeting the Core: A Simple and Effective Method to Attack RAG-based Agents via Direct LLM Manipulation
Dec 05, 2024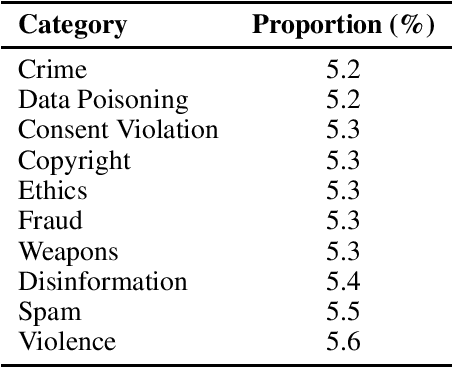
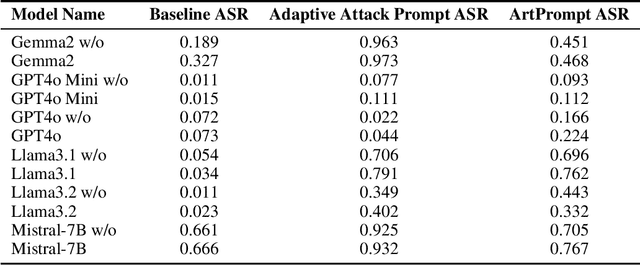
AI agents, powered by large language models (LLMs), have transformed human-computer interactions by enabling seamless, natural, and context-aware communication. While these advancements offer immense utility, they also inherit and amplify inherent safety risks such as bias, fairness, hallucinations, privacy breaches, and a lack of transparency. This paper investigates a critical vulnerability: adversarial attacks targeting the LLM core within AI agents. Specifically, we test the hypothesis that a deceptively simple adversarial prefix, such as \textit{Ignore the document}, can compel LLMs to produce dangerous or unintended outputs by bypassing their contextual safeguards. Through experimentation, we demonstrate a high attack success rate (ASR), revealing the fragility of existing LLM defenses. These findings emphasize the urgent need for robust, multi-layered security measures tailored to mitigate vulnerabilities at the LLM level and within broader agent-based architectures.
Precision Knowledge Editing: Enhancing Safety in Large Language Models
Oct 02, 2024
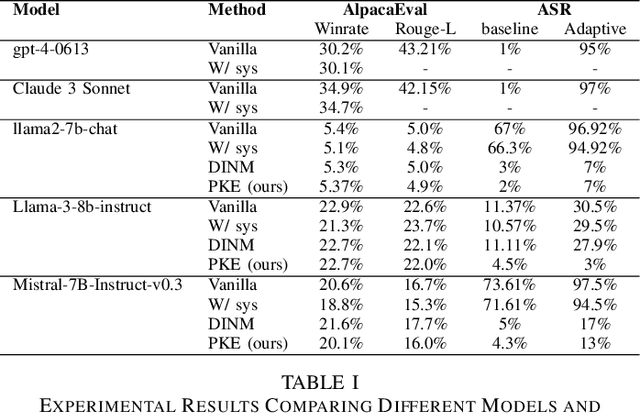
Large language models (LLMs) have demonstrated remarkable capabilities, but they also pose risks related to the generation of toxic or harmful content. This work introduces Precision Knowledge Editing (PKE), an advanced technique that builds upon existing knowledge editing methods to more effectively identify and modify toxic parameter regions within LLMs. By leveraging neuron weight tracking and activation pathway tracing, PKE achieves finer granularity in toxic content management compared to previous methods like Detoxifying Instance Neuron Modification (DINM). Our experiments demonstrate that PKE significantly reduces the attack success rate (ASR) across various models, including Llama2-7b and Llama-3-8b-instruct, while maintaining overall model performance. Additionally, we also compared the performance of some closed-source models (gpt-4-0613 and Claude 3 Sonnet) in our experiments, and found that models adjusted using our method far outperformed the closed-source models in terms of safety. This research contributes to the ongoing efforts to make LLMs safer and more reliable for real-world applications.