 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting the Core: A Simple and Effective Method to Attack RAG-based Agents via Direct LLM Manipulation
Paper and Code
Dec 05, 2024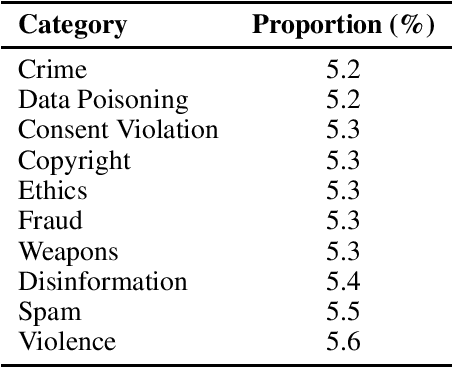
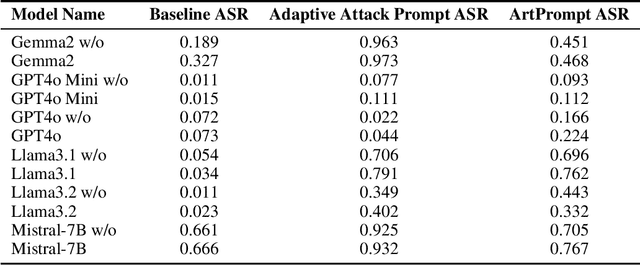
AI agents, powered by large language models (LLMs), have transformed human-computer interactions by enabling seamless, natural, and context-aware communication. While these advancements offer immense utility, they also inherit and amplify inherent safety risks such as bias, fairness, hallucinations, privacy breaches, and a lack of transparency. This paper investigates a critical vulnerability: adversarial attacks targeting the LLM core within AI agents. Specifically, we test the hypothesis that a deceptively simple adversarial prefix, such as \textit{Ignore the document}, can compel LLMs to produce dangerous or unintended outputs by bypassing their contextual safeguards. Through experimentation, we demonstrate a high attack success rate (ASR), revealing the fragility of existing LLM defenses. These findings emphasize the urgent need for robust, multi-layered security measures tailored to mitigate vulnerabilities at the LLM level and within broader agent-based architectures.