 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
Mapping Spiking Neural Networks to Neuromorphic Hardware
Sep 04, 2019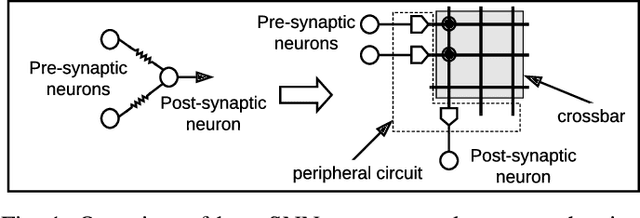
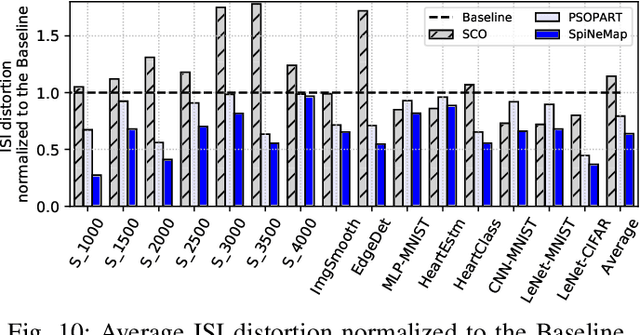
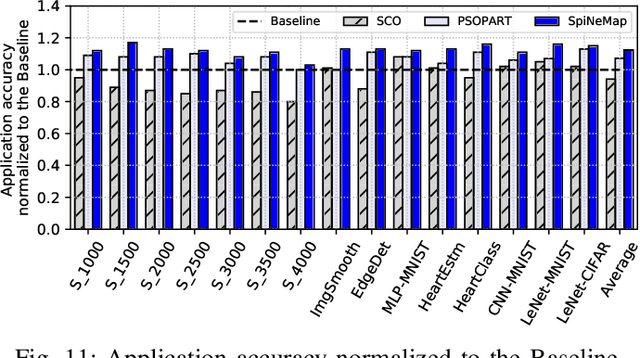
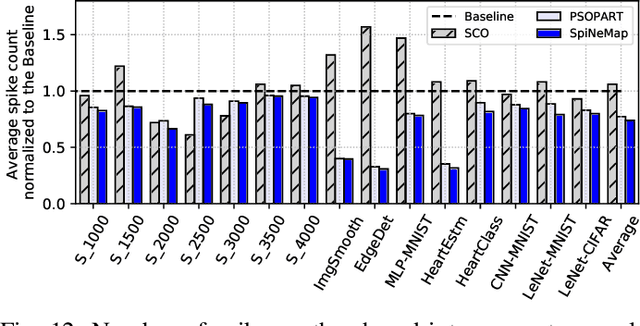
Neuromorphic hardware platforms implement biological neurons and synapses to execute spiking neural networks (SNNs) in an energy-efficient manner. We present SpiNeMap, a design methodology to map SNNs to crossbar-based neuromorphic hardware, minimizing spike latency and energy consumption. SpiNeMap operates in two steps: SpiNeCluster and SpiNePlacer. SpiNeCluster is a heuristic-based clustering technique to partition SNNs into clusters of synapses, where intracluster local synapses are mapped within crossbars of the hardware and inter-cluster global synapses are mapped to the shared interconnect. SpiNeCluster minimizes the number of spikes on global synapses, which reduces spike congestion on the shared interconnect, improving application performance. SpiNePlacer then finds the best placement of local and global synapses on the hardware using a meta-heuristic-based approach to minimize energy consumption and spike latency. We evaluate SpiNeMap using synthetic and realistic SNNs on the DynapSE neuromorphic hardware. We show that SpiNeMap reduces average energy consumption by 45% and average spike latency by 21%, compared to state-of-the-art techniques.
Mapping of Local and Global Synapses on Spiking Neuromorphic Hardware
Aug 13, 2019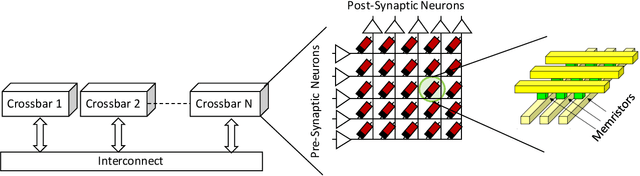
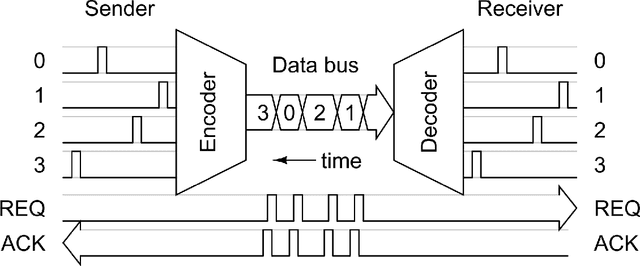
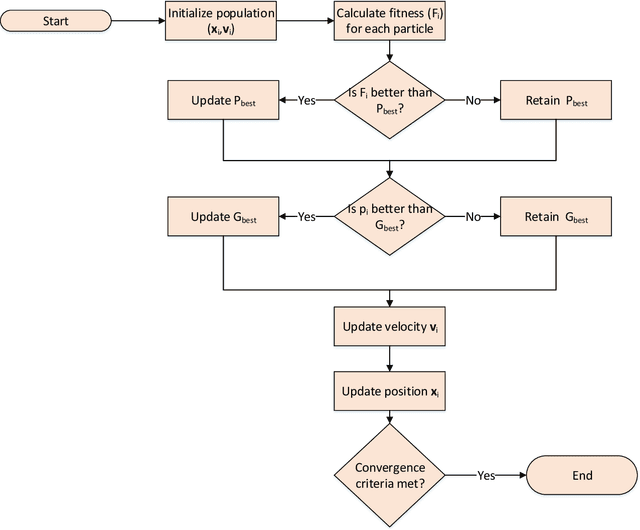
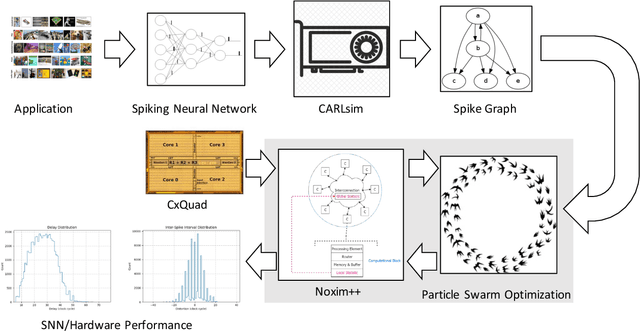
Spiking Neural Networks (SNNs) are widely deployed to solve complex pattern recognition, function approximation and image classification tasks. With the growing size and complexity of these networks, hardware implementation becomes challenging because scaling up the size of a single array (crossbar) of fully connected neurons is no longer feasible due to strict energy budget. Modern neromorphic hardware integrates small-sized crossbars with time-multiplexed interconnects. Partitioning SNNs becomes essential in order to map them on neuromorphic hardware with the major aim to reduce the global communication latency and energy overhead. To achieve this goal, we propose our instantiation of particle swarm optimization, which partitions SNNs into local synapses (mapped on crossbars) and global synapses (mapped on time-multiplexed interconnects), with the objective of reducing spike communication on the interconnect. This improves latency, power consumption as well as application performance by reducing inter-spike interval distortion and spike disorders. Our framework is implemented in Python, interfacing CARLsim, a GPU-accelerated application-level spiking neural network simulator with an extended version of Noxim, for simulating time-multiplexed interconnects. Experiments are conducted with realistic and synthetic SNN-based applications with different computation models, topologies and spike coding schemes. Using power numbers from in-house neuromorphic chips, we demonstrate significant reductions in energy consumption and spike latency over PACMAN, the widely-used partitioning technique for SNNs on SpiNNaker.