 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative Convergence or Imitation? Genre-Specific Homogeneity in LLM-Generated Chinese Literature
Mar 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in narrative generation. However, they often produce structurally homogenized stories, frequently following repetitive arrangements and combinations of plot events along with stereotypical resolutions. In this paper, we propose a novel theoretical framework for analysis by incorporating Proppian narratology and narrative functions. This framework is used to analyze the composition of narrative texts generated by LLMs to uncover their underlying narrative logic. Taking Chinese web literature as our research focus, we extend Propp's narrative theory, defining 34 narrative functions suited to modern web narrative structures. We further construct a human-annotated corpus to support the analysis of narrative structures within LLM-generated text. Experiments reveal that the primary reasons for the singular narrative logic and severe homogenization in generated texts are that current LLMs are unable to correctly comprehend the meanings of narrative functions and instead adhere to rigid narrative generation paradigms.
Long text outline generation: Chinese text outline based on unsupervised framework and large language mode
Dec 01, 2024
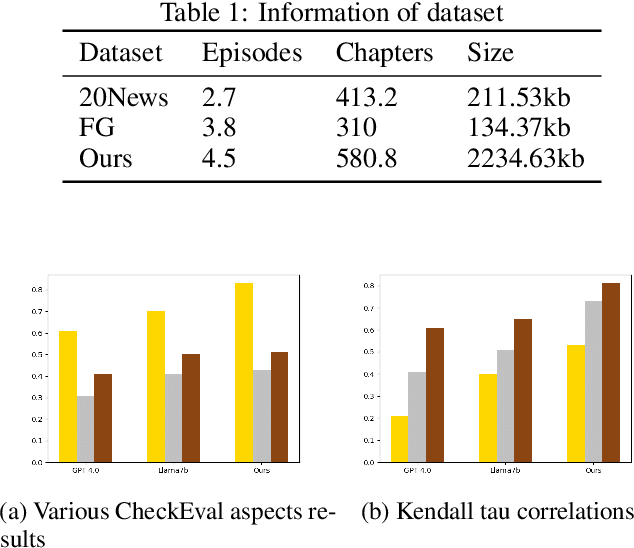


Outline generation aims to reveal the internal structure of a document by identifying underlying chapter relationships and generating corresponding chapter summaries. Although existing deep learning methods and large models perform well on small- and medium-sized texts, they struggle to produce readable outlines for very long texts (such as fictional works), often failing to segment chapters coherently. In this paper, we propose a novel outline generation method for Chinese, combining an unsupervised framework with large models. Specifically, the method first generates chapter feature graph data based on entity and syntactic dependency relationships. Then, a representation module based on graph attention layers learns deep embeddings of the chapter graph data. Using these chapter embeddings, we design an operator based on Markov chain principles to segment plot boundaries. Finally, we employ a large model to generate summaries of each plot segment and produce the overall outline. We evaluate our model based on segmentation accuracy and outline readability, and our performance outperforms several deep learning models and large models in comparative evaluations.
Masked AutoEncoder for Graph Clustering without Pre-defined Cluster Number k
Jan 09, 2024Graph clustering algorithms with autoencoder structures have recently gained popularity due to their efficient performance and low training cost. However, for existing graph autoencoder clustering algorithms based on GCN or GAT, not only do they lack good generalization ability, but also the number of clusters clustered by such autoencoder models is difficult to determine automatically. To solve this problem, we propose a new framework called Graph Clustering with Masked Autoencoders (GCMA). It employs our designed fusion autoencoder based on the graph masking method for the fusion coding of graph. It introduces our improved density-based clustering algorithm as a second decoder while decoding with multi-target reconstruction. By decoding the mask embedding, our model can capture more generalized and comprehensive knowledge. The number of clusters and clustering results can be output end-to-end while improving the generalization ability. As a nonparametric class method, extensive experiments demonstrate the superiority of \textit{GCMA} over state-of-the-art baselines.