 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootOOD: Self-Supervised Out-of-Distribution Detection via Synthetic Sample Exposure under Neural Collapse
Nov 17, 2025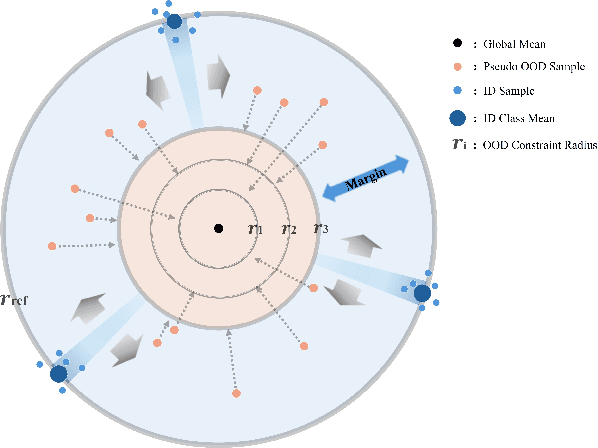
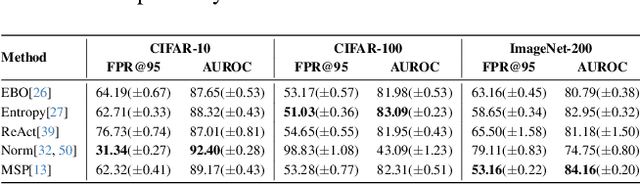
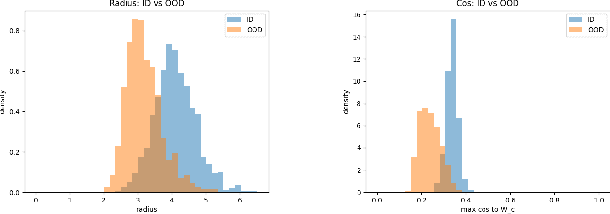
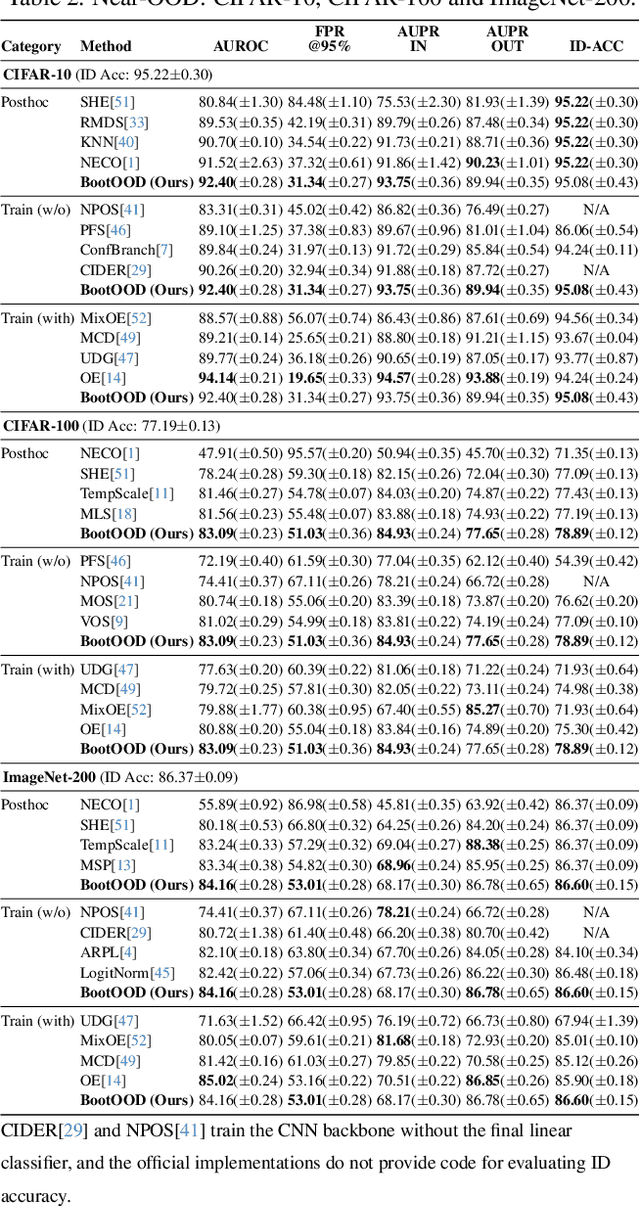
Out-of-distribution (OOD) detection is critical for deploying image classifiers in safety-sensitive environments, yet existing detectors often struggle when OOD samples are semantically similar to the in-distribution (ID) classes. We present BootOOD, a fully self-supervised OOD detection framework that bootstraps exclusively from ID data and is explicitly designed to handle semantically challenging OOD samples. BootOOD synthesizes pseudo-OOD features through simple transformations of ID representations and leverages Neural Collapse (NC), where ID features cluster tightly around class means with consistent feature norms. Unlike prior approaches that aim to constrain OOD features into subspaces orthogonal to the collapsed ID means, BootOOD introduces a lightweight auxiliary head that performs radius-based classification on feature norms. This design decouples OOD detection from the primary classifier and imposes a relaxed requirement: OOD samples are learned to have smaller feature norms than ID features, which is easier to satisfy when ID and OOD are semantically close. Experiments on CIFAR-10, CIFAR-100, and ImageNet-200 show that BootOOD outperforms prior post-hoc methods, surpasses training-based methods without outlier exposure, and is competitive with state-of-the-art outlier-exposure approaches while maintaining or improving ID accuracy.
Out-of-distribution Generalization for Total Variation based Invariant Risk Minimization
Feb 28, 2025



Invariant risk minimization is an important general machine learning framework that has recently been interpreted as a total variation model (IRM-TV). However, how to improve out-of-distribution (OOD) generalization in the IRM-TV setting remains unsolved. In this paper, we extend IRM-TV to a Lagrangian multiplier model named OOD-TV-IRM. We find that the autonomous TV penalty hyperparameter is exactly the Lagrangian multiplier. Thus OOD-TV-IRM is essentially a primal-dual optimization model, where the primal optimization minimizes the entire invariant risk and the dual optimization strengthens the TV penalty. The objective is to reach a semi-Nash equilibrium where the balance between the training loss and OOD generalization is maintained. We also develop a convergent primal-dual algorithm that facilitates an adversarial learning scheme. Experimental results show that OOD-TV-IRM outperforms IRM-TV in most situations.
Explaining the Attention Mechanism of End-to-End Speech Recognition Using Decision Trees
Oct 08, 2021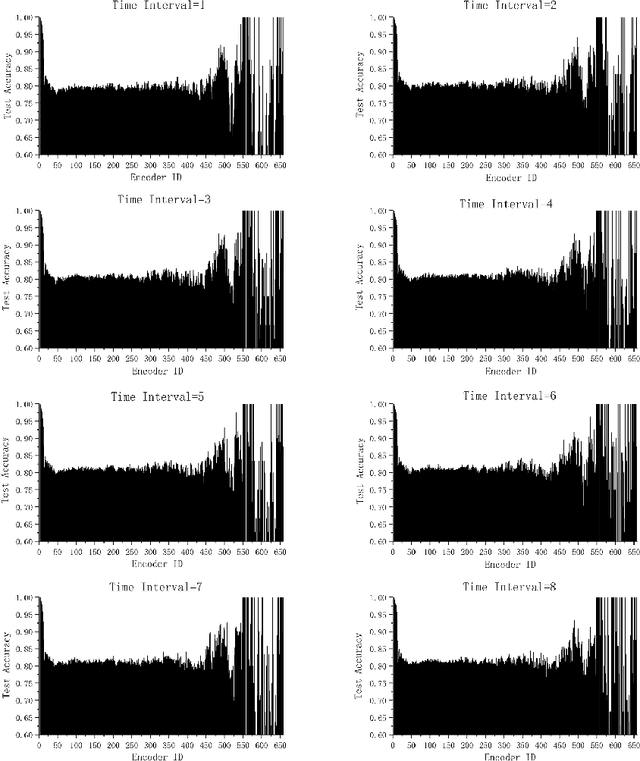
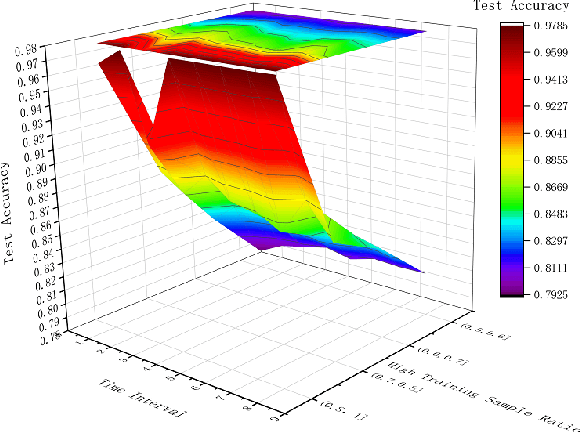
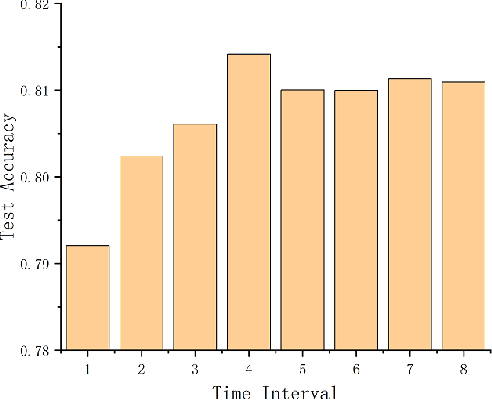
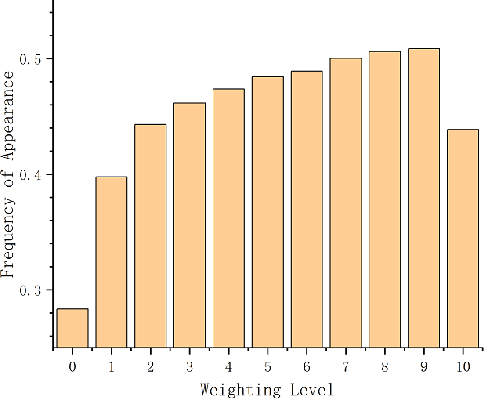
The attention mechanism has largely improved the performance of end-to-end speech recognition systems. However, the underlying behaviours of attention is not yet clearer. In this study, we use decision trees to explain how the attention mechanism impact itself in speech recognition. The results indicate that attention levels are largely impacted by their previous states rather than the encoder and decoder patterns. Additionally, the default attention mechanism seems to put more weights on closer states, but behaves poorly on modelling long-term dependencies of attention states.