 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective and Differentiated Use of Control Information for Multi-speaker Speech Synthesis
Jul 08, 2021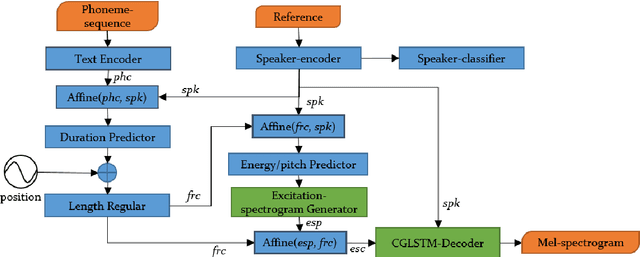

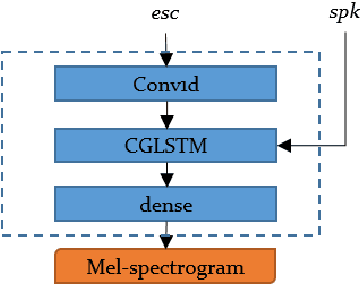
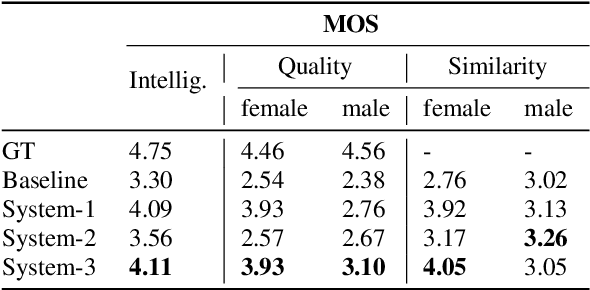
In multi-speaker speech synthesis, data from a number of speakers usually tends to have great diversity due to the fact that the speakers may differ largely in their ages, speaking styles, speeds, emotions, and so on. The diversity of data will lead to the one-to-many mapping problem \cite{Ren2020FastSpeech2F, Kumar2020FewSA}. It is important but challenging to improve the modeling capabilities for multi-speaker speech synthesis. To address the issue, this paper researches into the effective use of control information such as speaker and pitch which are differentiated from text-content information in our encoder-decoder framework: 1) Design a representation of harmonic structure of speech, called excitation spectrogram, from pitch and energy. The excitation spectrogrom is, along with the text-content, fed to the decoder to guide the learning of harmonics of mel-spectrogram. 2) Propose conditional gated LSTM (CGLSTM) whose input/output/forget gates are re-weighted by speaker embedding to control the flow of text-content information in the network. The experiments show significant reduction in reconstruction errors of mel-spectrogram in the training of multi-speaker generative model, and a great improvement is observed in the subjective evaluation of speaker adapted model, e.g, the Mean Opinion Score (MOS) of intelligibility increases by 0.81 points.