 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 14uJ/Decision Keyword Spotting Accelerator with In-SRAM-Computing and On Chip Learning for Customization
May 10, 2022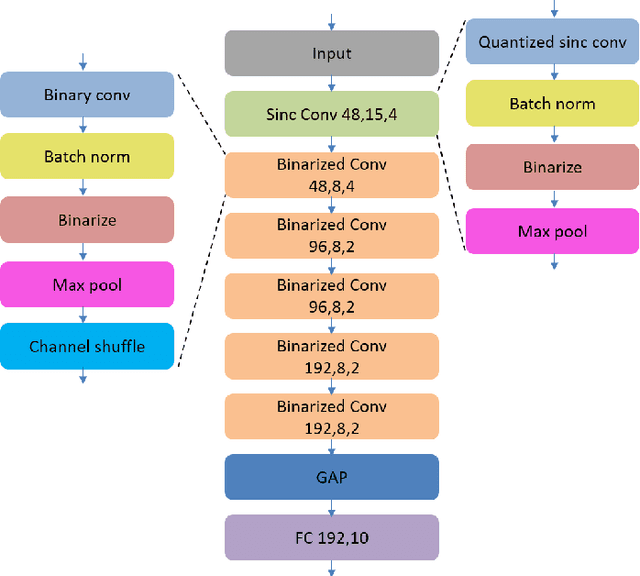
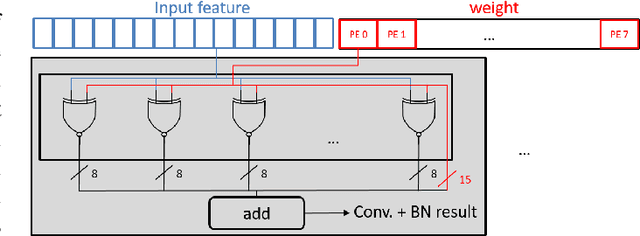
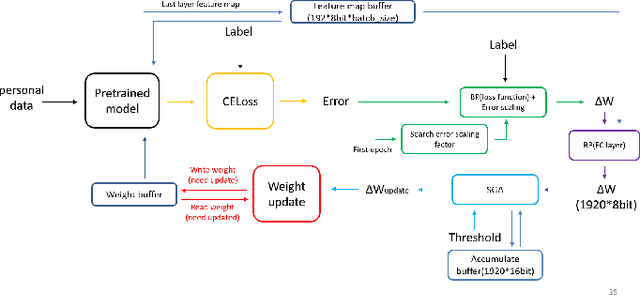
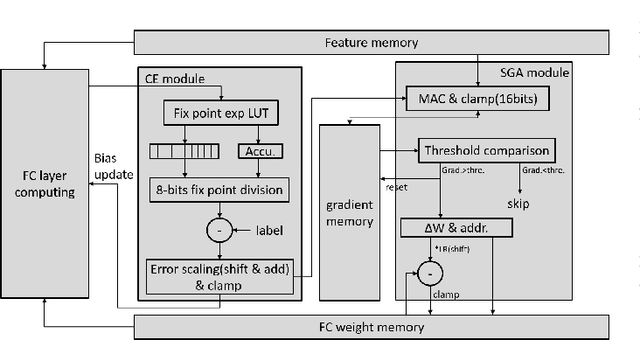
Keyword spotting has gained popularity as a natural way to interact with consumer devices in recent years. However, because of its always-on nature and the variety of speech, it necessitates a low-power design as well as user customization. This paper describes a low-power, energy-efficient keyword spotting accelerator with SRAM based in-memory computing (IMC) and on-chip learning for user customization. However, IMC is constrained by macro size, limited precision, and non-ideal effects. To address the issues mentioned above, this paper proposes bias compensation and fine-tuning using an IMC-aware model design. Furthermore, because learning with low-precision edge devices results in zero error and gradient values due to quantization, this paper proposes error scaling and small gradient accumulation to achieve the same accuracy as ideal model training. The simulation results show that with user customization, we can recover the accuracy loss from 51.08\% to 89.76\% with compensation and fine-tuning and further improve to 96.71\% with customization. The chip implementation can successfully run the model with only 14$uJ$ per decision. When compared to the state-of-the-art works, the presented design has higher energy efficiency with additional on-chip model customization capabilities for higher accuracy.
Hardware-Robust In-RRAM-Computing for Object Detection
May 09, 2022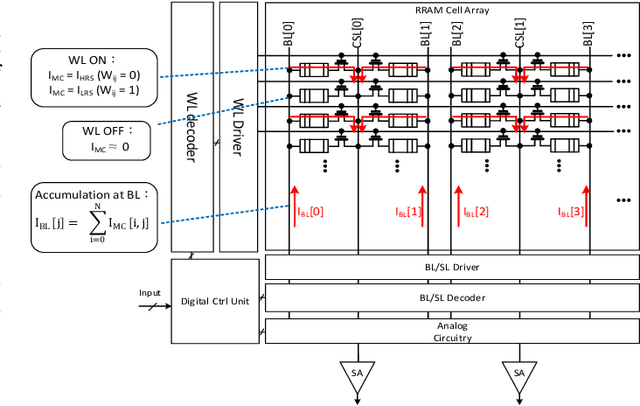
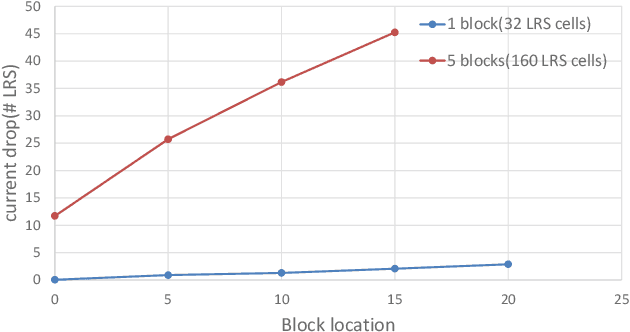
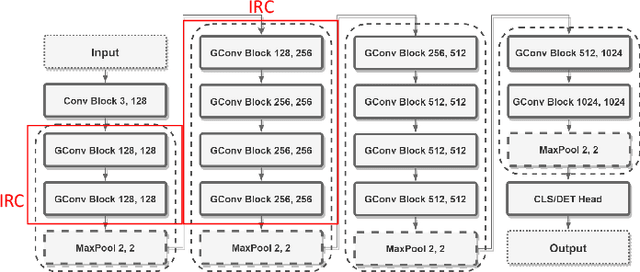
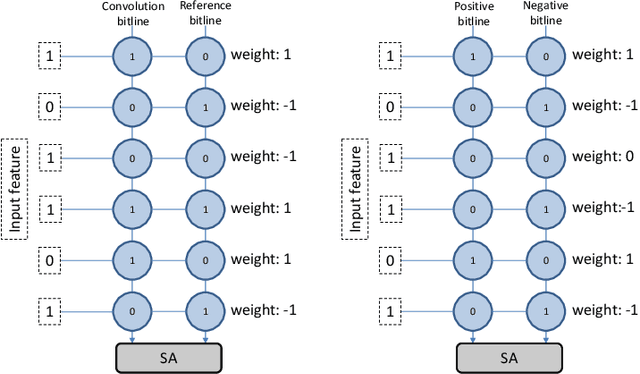
In-memory computing is becoming a popular architecture for deep-learning hardware accelerators recently due to its highly parallel computing, low power, and low area cost. However, in-RRAM computing (IRC) suffered from large device variation and numerous nonideal effects in hardware. Although previous approaches including these effects in model training successfully improved variation tolerance, they only considered part of the nonideal effects and relatively simple classification tasks. This paper proposes a joint hardware and software optimization strategy to design a hardware-robust IRC macro for object detection. We lower the cell current by using a low word-line voltage to enable a complete convolution calculation in one operation that minimizes the impact of nonlinear addition. We also implement ternary weight mapping and remove batch normalization for better tolerance against device variation, sense amplifier variation, and IR drop problem. An extra bias is included to overcome the limitation of the current sensing range. The proposed approach has been successfully applied to a complex object detection task with only 3.85\% mAP drop, whereas a naive design suffers catastrophic failure under these nonideal effects.