 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopEval: A Character-Level Approach to End-To-End Evaluation Compatible with Word-Level Benchmark Dataset
Aug 29, 2019



The most prevalent scope of interest for OCR applications used to be scanned documents, but it has now shifted towards the natural scene. Despite the change of times, the existing evaluation methods are still based on the old criteria suited better for the past interests. In this paper, we propose PopEval, a novel evaluation approach for the recent OCR interests. The new and past evaluation algorithms were compared through the results on various datasets and OCR models. Compared to the other evaluation methods, the proposed evaluation algorithm was closer to the human's qualitative evaluation than other existing methods. Although the evaluation algorithm was devised as a character-level approach, the comparative experiment revealed that PopEval is also compatible on existing benchmark datasets annotated at word-level. The proposed evaluation algorithm is not only applicable to current end-to-end tasks, but also suggests a new direction to redesign the evaluation concept for further OCR researches.
Simultaneous Recognition of Horizontal and Vertical Text in Natural Images
Dec 06, 2018
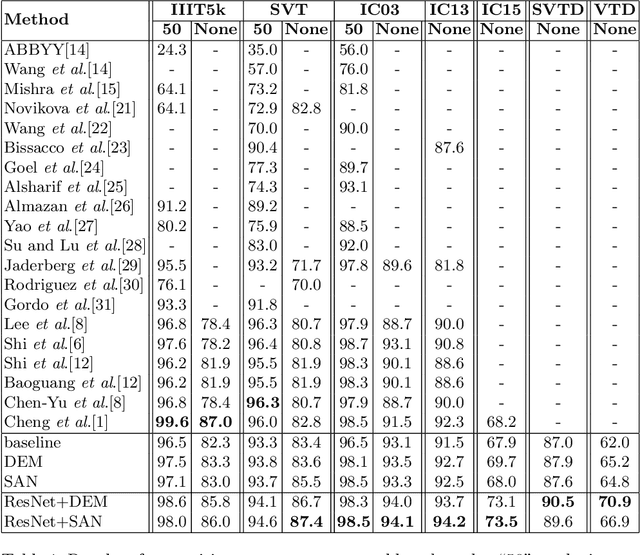
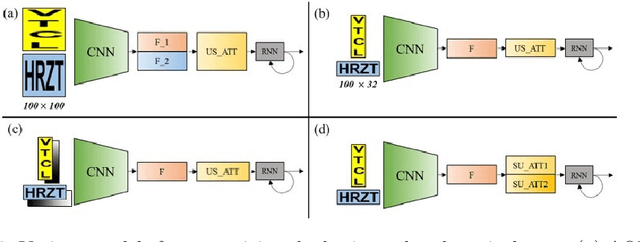

Recent state-of-the-art scene text recognition methods have primarily focused on horizontal text in images. However, in several Asian countries, including China, large amounts of text in signs, books, and TV commercials are vertically directed. Because the horizontal and vertical texts exhibit different characteristics, developing an algorithm that can simultaneously recognize both types of text in real environments is necessary. To address this problem, we adopted the direction encoding mask (DEM) and selective attention network (SAN) methods based on supervised learning. DEM contains directional information to compensate in cases that lack text direction; therefore, our network is trained using this information to handle the vertical text. The SAN method is designed to work individually for both types of text. To train the network to recognize both types of text and to evaluate the effectiveness of the designed model, we prepared a new synthetic vertical text dataset and collected an actual vertical text dataset (VTD142) from the Web. Using these datasets, we proved that our proposed model can accurately recognize both vertical and horizontal text and can achieve state-of-the-art results in experiments using benchmark datasets, including the street view test (SVT), IIIT-5k, and ICDAR. Although our model is relatively simple as compared to its predecessors, it maintains the accuracy and is trained in an end-to-end manner.