 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprisingly Straightforward Scene Text Removal Method With Gated Attention and Region of Interest Generation: A Comprehensive Prominent Model Analysis
Oct 14, 2022
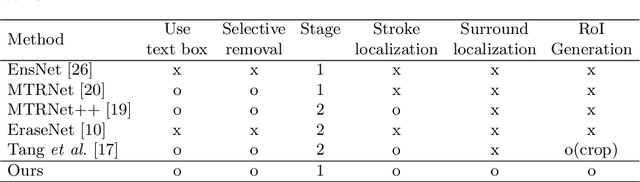
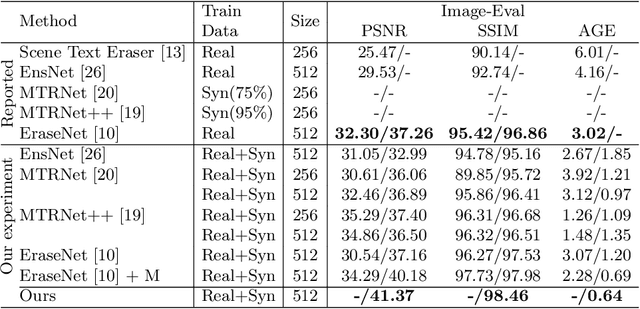
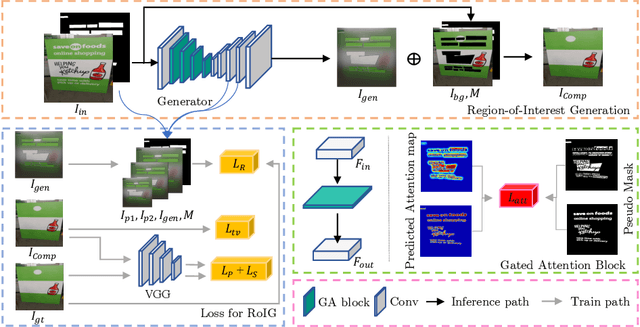
Scene text removal (STR), a task of erasing text from natural scene images, has recently attracted attention as an important component of editing text or concealing private information such as ID, telephone, and license plate numbers. While there are a variety of different methods for STR actively being researched, it is difficult to evaluate superiority because previously proposed methods do not use the same standardized training/evaluation dataset. We use the same standardized training/testing dataset to evaluate the performance of several previous methods after standardized re-implementation. We also introduce a simple yet extremely effective Gated Attention (GA) and Region-of-Interest Generation (RoIG) methodology in this paper. GA uses attention to focus on the text stroke as well as the textures and colors of the surrounding regions to remove text from the input image much more precisely. RoIG is applied to focus on only the region with text instead of the entire image to train the model more efficiently. Experimental results on the benchmark dataset show that our method significantly outperforms existing state-of-the-art methods in almost all metrics with remarkably higher-quality results. Furthermore, because our model does not generate a text stroke mask explicitly, there is no need for additional refinement steps or sub-models, making our model extremely fast with fewer parameters. The dataset and code are available at this https://github.com/naver/garnet.
PopEval: A Character-Level Approach to End-To-End Evaluation Compatible with Word-Level Benchmark Dataset
Aug 29, 2019



The most prevalent scope of interest for OCR applications used to be scanned documents, but it has now shifted towards the natural scene. Despite the change of times, the existing evaluation methods are still based on the old criteria suited better for the past interests. In this paper, we propose PopEval, a novel evaluation approach for the recent OCR interests. The new and past evaluation algorithms were compared through the results on various datasets and OCR models. Compared to the other evaluation methods, the proposed evaluation algorithm was closer to the human's qualitative evaluation than other existing methods. Although the evaluation algorithm was devised as a character-level approach, the comparative experiment revealed that PopEval is also compatible on existing benchmark datasets annotated at word-level. The proposed evaluation algorithm is not only applicable to current end-to-end tasks, but also suggests a new direction to redesign the evaluation concept for further OCR researches.
Simultaneous Recognition of Horizontal and Vertical Text in Natural Images
Dec 06, 2018
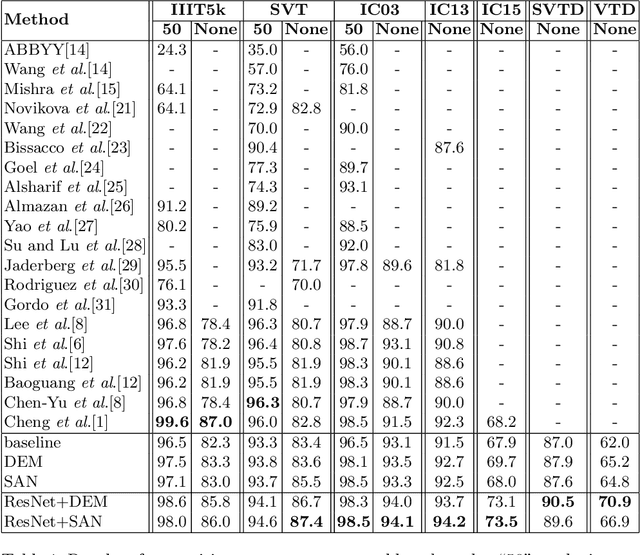
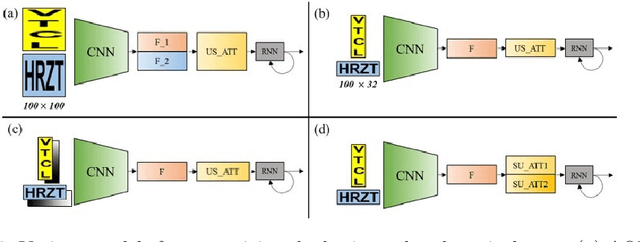

Recent state-of-the-art scene text recognition methods have primarily focused on horizontal text in images. However, in several Asian countries, including China, large amounts of text in signs, books, and TV commercials are vertically directed. Because the horizontal and vertical texts exhibit different characteristics, developing an algorithm that can simultaneously recognize both types of text in real environments is necessary. To address this problem, we adopted the direction encoding mask (DEM) and selective attention network (SAN) methods based on supervised learning. DEM contains directional information to compensate in cases that lack text direction; therefore, our network is trained using this information to handle the vertical text. The SAN method is designed to work individually for both types of text. To train the network to recognize both types of text and to evaluate the effectiveness of the designed model, we prepared a new synthetic vertical text dataset and collected an actual vertical text dataset (VTD142) from the Web. Using these datasets, we proved that our proposed model can accurately recognize both vertical and horizontal text and can achieve state-of-the-art results in experiments using benchmark datasets, including the street view test (SVT), IIIT-5k, and ICDAR. Although our model is relatively simple as compared to its predecessors, it maintains the accuracy and is trained in an end-to-end manner.