 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs and Social Media to Understand User Perception of Smartphone-Based Earthquake Early Warnings
Mar 24, 2026Android's Earthquake Alert (AEA) system provided timely early warnings to millions during the Mw 6.2 Marmara Ereglisi, Türkiye earthquake on April 23, 2025. This event, the largest in the region in 25 years, served as a critical real-world test for smartphone-based Earthquake Early Warning (EEW) systems. The AEA system successfully delivered alerts to users with high precision, offering over a minute of warning before the strongest shaking reached urban areas. This study leveraged Large Language Models (LLMs) to analyze more than 500 public social media posts from the X platform, extracting 42 distinct attributes related to user experience and behavior. Statistical analyses revealed significant relationships, notably a strong correlation between user trust and alert timeliness. Our results indicate a distinction between engineering and the user-centric definition of system accuracy. We found that timeliness is accuracy in the user's mind. Overall, this study provides actionable insights for optimizing alert design, public education campaigns, and future behavioral research to improve the effectiveness of such systems in seismically active regions.
Gemini & Physical World: Large Language Models Can Estimate the Intensity of Earthquake Shaking from Multi-Modal Social Media Posts
May 29, 2024This paper presents a novel approach for estimating the ground shaking intensity using social media data and CCTV footage. Employing the Gemini Pro (Reid et al. 2024) model, a multi-modal language model, we demonstrate the ability to extract relevant information from unstructured data utilizing generative AI and natural language processing. The model output, in the form of Modified Mercalli Intensity (MMI) values, align well with independent observational data. Furthermore, our results suggest that beyond its advanced visual and auditory understanding abilities, Gemini appears to utilize additional sources of knowledge, including a simplified understanding of the general relationship between earthquake magnitude, distance, and MMI intensity, which it presumably acquired during its training, in its reasoning and decision-making processes. These findings raise intriguing questions about the extent of Gemini's general understanding of the physical world and its phenomena. The ability of Gemini to generate results consistent with established scientific knowledge highlights the potential of LLMs like Gemini in augmenting our understanding of complex physical phenomena such as earthquakes. More specifically, the results of this study highlight the potential of LLMs like Gemini to revolutionize citizen seismology by enabling rapid, effective, and flexible analysis of crowdsourced data from eyewitness accounts for assessing earthquake impact and providing crisis situational awareness. This approach holds great promise for improving early warning systems, disaster response, and overall resilience in earthquake-prone regions. This study provides a significant step toward harnessing the power of social media and AI for earthquake disaster mitigation.
Nonnegative Matrix Factorization for Semi-supervised Dimensionality Reduction
Dec 16, 2011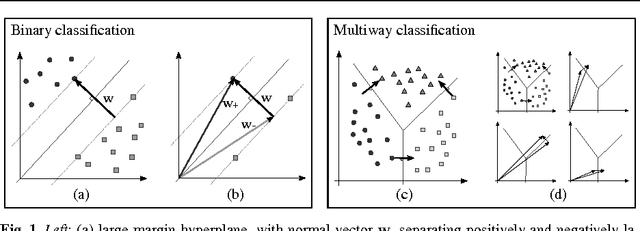

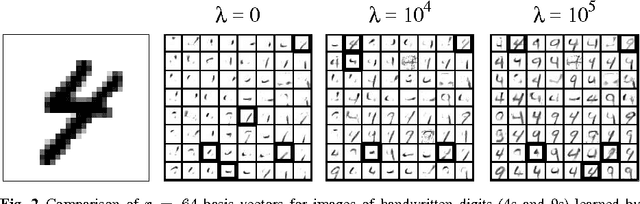

We show how to incorporate information from labeled examples into nonnegative matrix factorization (NMF), a popular unsupervised learning algorithm for dimensionality reduction. In addition to mapping the data into a space of lower dimensionality, our approach aims to preserve the nonnegative components of the data that are important for classification. We identify these components from the support vectors of large-margin classifiers and derive iterative updates to preserve them in a semi-supervised version of NMF. These updates have a simple multiplicative form like their unsupervised counterparts; they are also guaranteed at each iteration to decrease their loss function---a weighted sum of I-divergences that captures the trade-off between unsupervised and supervised learning. We evaluate these updates for dimensionality reduction when they are used as a precursor to linear classification. In this role, we find that they yield much better performance than their unsupervised counterparts. We also find one unexpected benefit of the low dimensional representations discovered by our approach: often they yield more accurate classifiers than both ordinary and transductive SVMs trained in the original input space.
Analysis and Extension of Arc-Cosine Kernels for Large Margin Classification
Dec 16, 2011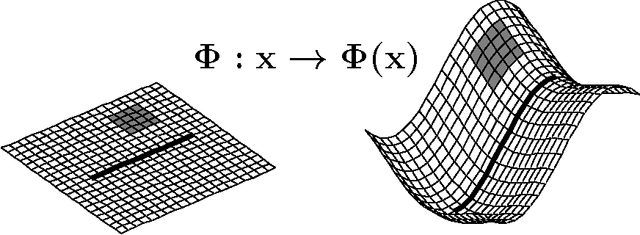
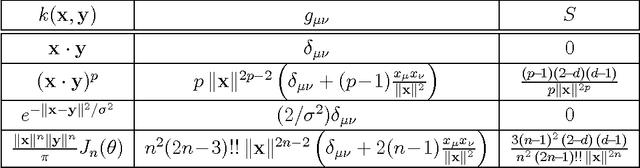
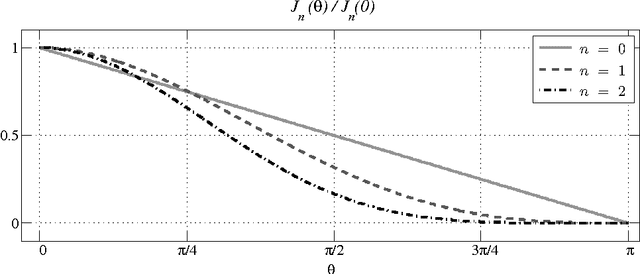
We investigate a recently proposed family of positive-definite kernels that mimic the computation in large neural networks. We examine the properties of these kernels using tools from differential geometry; specifically, we analyze the geometry of surfaces in Hilbert space that are induced by these kernels. When this geometry is described by a Riemannian manifold, we derive results for the metric, curvature, and volume element. Interestingly, though, we find that the simplest kernel in this family does not admit such an interpretation. We explore two variations of these kernels that mimic computation in neural networks with different activation functions. We experiment with these new kernels on several data sets and highlight their general trends in performance for classification.