 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm for Interpretable Graph Features via Motivic Persistent Cohomology
Dec 23, 2025We present the Chromatic Persistence Algorithm (CPA), an event-driven method for computing persistent cohomological features of weighted graphs via graphic arrangements, a classical object in computational geometry. We establish rigorous complexity results: CPA is exponential in the worst case, fixed-parameter tractable in treewidth, and nearly linear for common graph families such as trees, cycles, and series-parallel graphs. Finally, we demonstrate its practical applicability through a controlled experiment on molecular-like graph structures.
Top-K Exterior Power Persistent Homology: Algorithm, Structure, and Stability
Dec 23, 2025
Exterior powers play important roles in persistent homology in computational geometry. In the present paper we study the problem of extracting the $K$ longest intervals of the exterior-power layers of a tame persistence module. We prove a structural decomposition theorem that organizes the exterior-power layers into monotone per-anchor streams with explicit multiplicities, enabling a best-first algorithm. We also show that the Top-$K$ length vector is $2$-Lipschitz under bottleneck perturbations of the input barcode, and prove a comparison-model lower bound. Our experiments confirm the theory, showing speedups over full enumeration in high overlap cases. By enabling efficient extraction of the most prominent features, our approach makes higher-order persistence feasible for large datasets and thus broadly applicable to machine learning, data science, and scientific computing.
Accelerating Machine Learning Systems via Category Theory: Applications to Spherical Attention for Gene Regulatory Networks
May 14, 2025How do we enable artificial intelligence models to improve themselves? This is central to exponentially improving generalized artificial intelligence models, which can improve their own architecture to handle new problem domains in an efficient manner that leverages the latest hardware. However, current automated compilation methods are poor, and efficient algorithms require years of human development. In this paper, we use neural circuit diagrams, based in category theory, to prove a general theorem related to deep learning algorithms, guide the development of a novel attention algorithm catered to the domain of gene regulatory networks, and produce a corresponding efficient kernel. The algorithm we propose, spherical attention, shows that neural circuit diagrams enable a principled and systematic method for reasoning about deep learning architectures and providing high-performance code. By replacing SoftMax with an $L^2$ norm as suggested by diagrams, it overcomes the special function unit bottleneck of standard attention while retaining the streaming property essential to high-performance. Our diagrammatically derived \textit{FlashSign} kernel achieves comparable performance to the state-of-the-art, fine-tuned FlashAttention algorithm on an A100, and $3.6\times$ the performance of PyTorch. Overall, this investigation shows neural circuit diagrams' suitability as a high-level framework for the automated development of efficient, novel artificial intelligence architectures.
Computing with Categories in Machine Learning
Mar 07, 2023Category theory has been successfully applied in various domains of science, shedding light on universal principles unifying diverse phenomena and thereby enabling knowledge transfer between them. Applications to machine learning have been pursued recently, and yet there is still a gap between abstract mathematical foundations and concrete applications to machine learning tasks. In this paper we introduce DisCoPyro as a categorical structure learning framework, which combines categorical structures (such as symmetric monoidal categories and operads) with amortized variational inference, and can be applied, e.g., in program learning for variational autoencoders. We provide both mathematical foundations and concrete applications together with comparison of experimental performance with other models (e.g., neuro-symbolic models). We speculate that DisCoPyro could ultimately contribute to the development of artificial general intelligence.
A Probabilistic Generative Model of Free Categories
May 13, 2022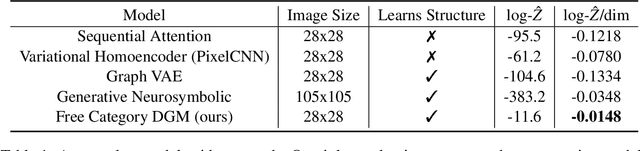

Applied category theory has recently developed libraries for computing with morphisms in interesting categories, while machine learning has developed ways of learning programs in interesting languages. Taking the analogy between categories and languages seriously, this paper defines a probabilistic generative model of morphisms in free monoidal categories over domain-specific generating objects and morphisms. The paper shows how acyclic directed wiring diagrams can model specifications for morphisms, which the model can use to generate morphisms. Amortized variational inference in the generative model then enables learning of parameters (by maximum likelihood) and inference of latent variables (by Bayesian inversion). A concrete experiment shows that the free category prior achieves competitive reconstruction performance on the Omniglot dataset.
The Artificial Scientist: Logicist, Emergentist, and Universalist Approaches to Artificial General Intelligence
Oct 05, 2021We attempt to define what is necessary to construct an Artificial Scientist, explore and evaluate several approaches to artificial general intelligence (AGI) which may facilitate this, conclude that a unified or hybrid approach is necessary and explore two theories that satisfy this requirement to some degree.
Philosophical Specification of Empathetic Ethical Artificial Intelligence
Jul 22, 2021In order to construct an ethical artificial intelligence (AI) two complex problems must be overcome. Firstly, humans do not consistently agree on what is or is not ethical. Second, contemporary AI and machine learning methods tend to be blunt instruments which either search for solutions within the bounds of predefined rules, or mimic behaviour. An ethical AI must be capable of inferring unspoken rules, interpreting nuance and context, possess and be able to infer intent, and explain not just its actions but its intent. Using enactivism, semiotics, perceptual symbol systems and symbol emergence, we specify an agent that learns not just arbitrary relations between signs but their meaning in terms of the perceptual states of its sensorimotor system. Subsequently it can learn what is meant by a sentence and infer the intent of others in terms of its own experiences. It has malleable intent because the meaning of symbols changes as it learns, and its intent is represented symbolically as a goal. As such it may learn a concept of what is most likely to be considered ethical by the majority within a population of humans, which may then be used as a goal. The meaning of abstract symbols is expressed using perceptual symbols of raw sensorimotor stimuli as the weakest (consistent with Ockham's Razor) necessary and sufficient concept, an intensional definition learned from an ostensive definition, from which the extensional definition or category of all ethical decisions may be obtained. Because these abstract symbols are the same for both situation and response, the same symbol is used when either performing or observing an action. This is akin to mirror neurons in the human brain. Mirror symbols may allow the agent to empathise, because its own experiences are associated with the symbol, which is also associated with the observation of another agent experiencing something that symbol represents.
Intensional Artificial Intelligence: From Symbol Emergence to Explainable and Empathetic AI
Apr 23, 2021We argue that an explainable artificial intelligence must possess a rationale for its decisions, be able to infer the purpose of observed behaviour, and be able to explain its decisions in the context of what its audience understands and intends. To address these issues we present four novel contributions. Firstly, we define an arbitrary task in terms of perceptual states, and discuss two extremes of a domain of possible solutions. Secondly, we define the intensional solution. Optimal by some definitions of intelligence, it describes the purpose of a task. An agent possessed of it has a rationale for its decisions in terms of that purpose, expressed in a perceptual symbol system grounded in hardware. Thirdly, to communicate that rationale requires natural language, a means of encoding and decoding perceptual states. We propose a theory of meaning in which, to acquire language, an agent should model the world a language describes rather than the language itself. If the utterances of humans are of predictive value to the agent's goals, then the agent will imbue those utterances with meaning in terms of its own goals and perceptual states. In the context of Peircean semiotics, a community of agents must share rough approximations of signs, referents and interpretants in order to communicate. Meaning exists only in the context of intent, so to communicate with humans an agent must have comparable experiences and goals. An agent that learns intensional solutions, compelled by objective functions somewhat analogous to human motivators such as hunger and pain, may be capable of explaining its rationale not just in terms of its own intent, but in terms of what its audience understands and intends. It forms some approximation of the perceptual states of humans.
Feature visualization of Raman spectrum analysis with deep convolutional neural network
Jul 27, 2020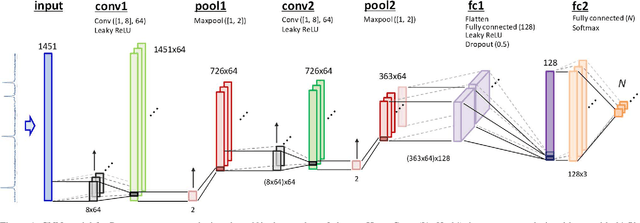
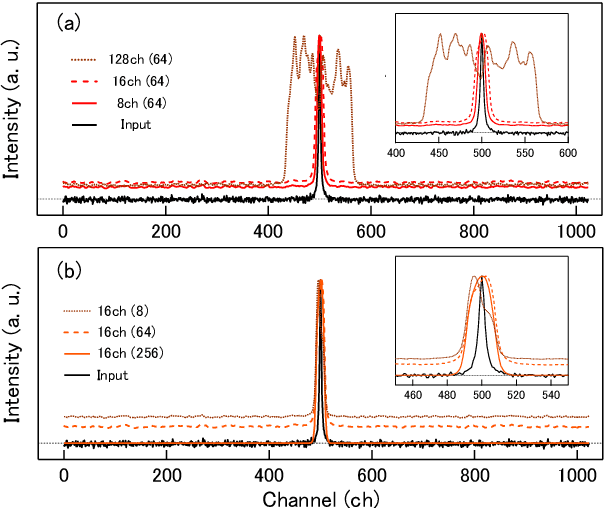
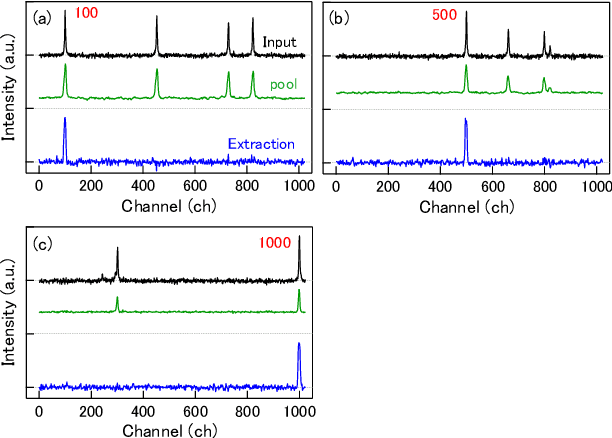
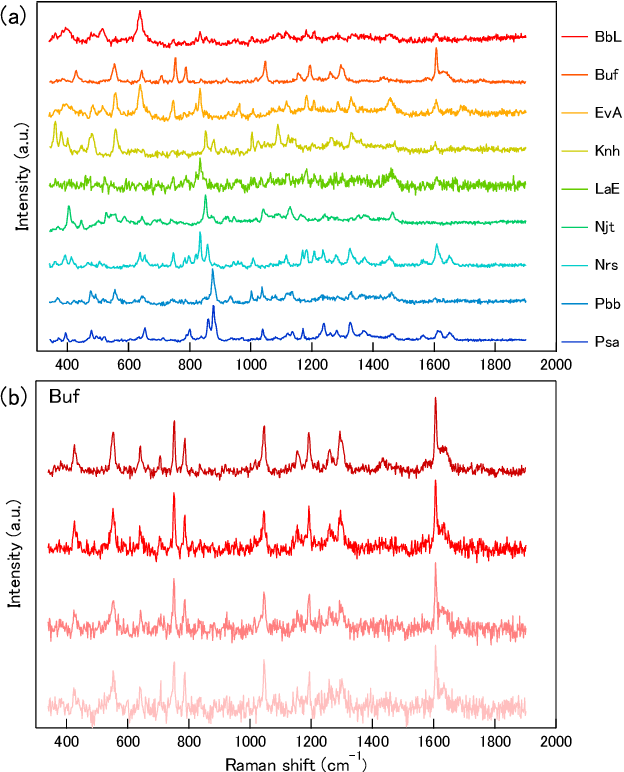
We demonstrate a recognition and feature visualization method that uses a deep convolutional neural network for Raman spectrum analysis. The visualization is achieved by calculating important regions in the spectra from weights in pooling and fully-connected layers. The method is first examined for simple Lorentzian spectra, then applied to the spectra of pharmaceutical compounds and numerically mixed amino acids. We investigate the effects of the size and number of convolution filters on the extracted regions for Raman-peak signals using the Lorentzian spectra. It is confirmed that the Raman peak contributes to the recognition by visualizing the extracted features. A near-zero weight value is obtained at the background level region, which appears to be used for baseline correction. Common component extraction is confirmed by an evaluation of numerically mixed amino acid spectra. High weight values at the common peaks and negative values at the distinctive peaks appear, even though the model is given one-hot vectors as the training labels (without a mix ratio). This proposed method is potentially suitable for applications such as the validation of trained models, ensuring the reliability of common component extraction from compound samples for spectral analysis.