 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete Power Reallocation for MU-MIMO under Per-Antenna Power Constraint
Feb 12, 2021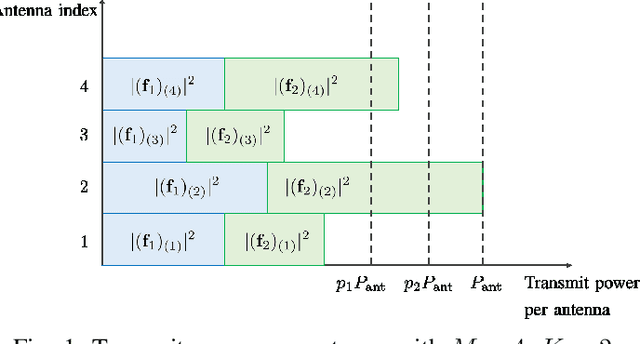
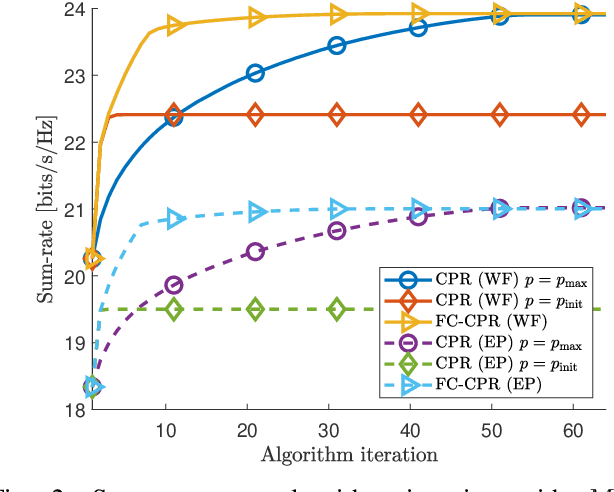
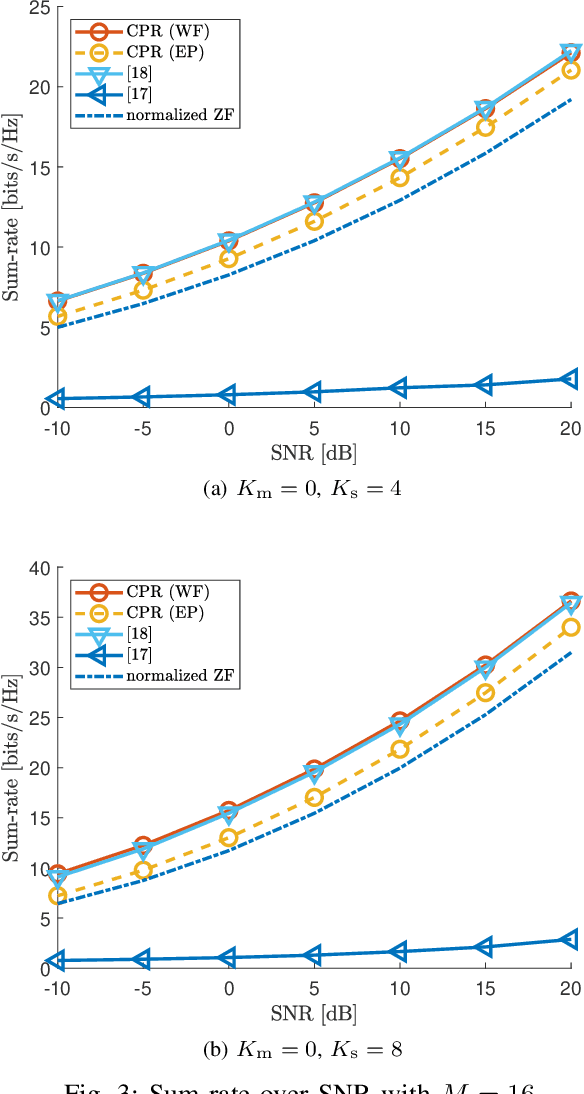
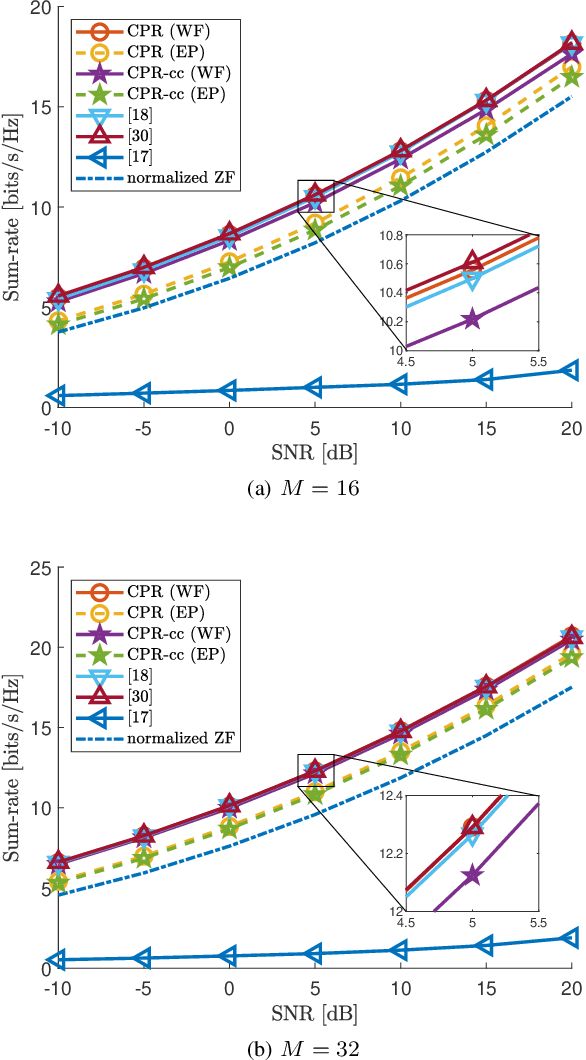
This paper proposes a beamforming method under a per-antenna power constraint (PAPC). Although many beamformer designs with the PAPC need to solve complex optimization problems, the proposed complete power reallocation (CPR) method can generate beamformers with excellent performance only with linear operations. CPR is designed to have a simple structure, making it highly flexible and practical. In this paper, three CPR variations considering algorithm convergence speed, sum-rate maximization, and robustness to channel uncertainty are developed. Simulation results verify that CPR and its variations satisfy their design criteria, and, hence, CPR can be readily utilized for various purposes.
Massive MIMO Channel Prediction: Kalman Filtering vs. Machine Learning
Sep 21, 2020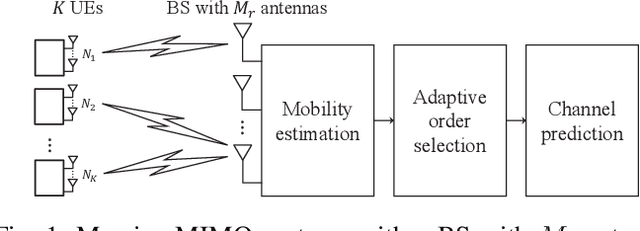
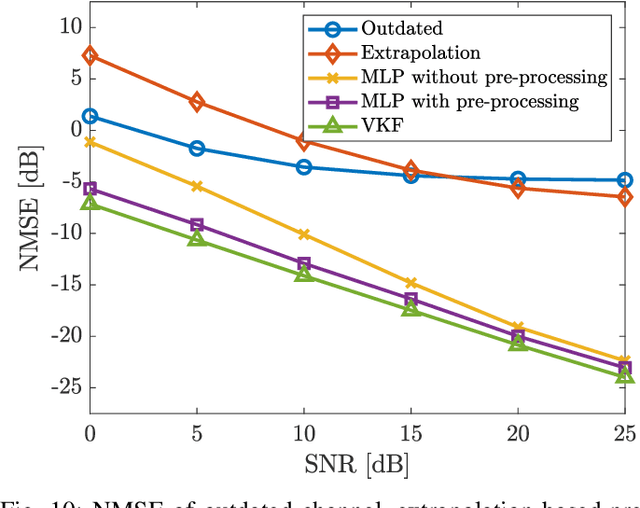
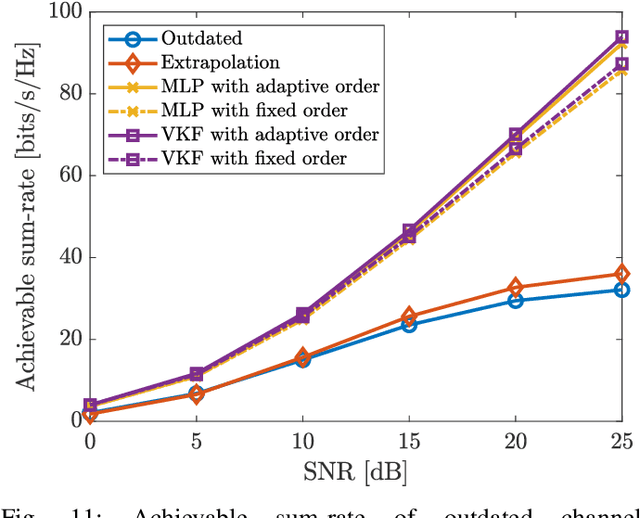
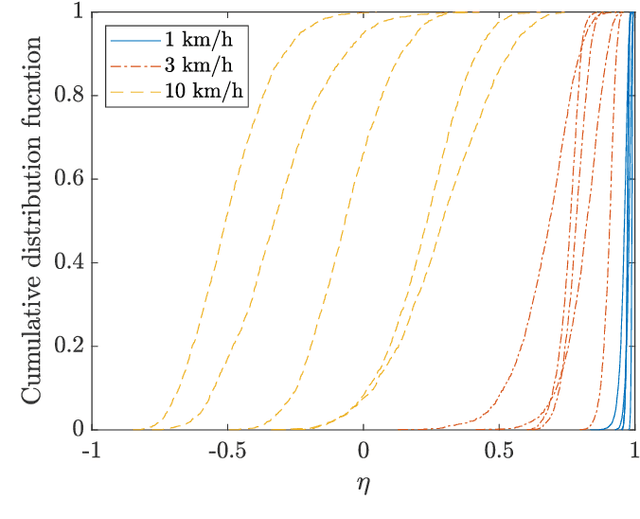
This paper focuses on channel prediction techniques for massive multiple-input multiple-output (MIMO) systems. Previous channel predictors are based on theoretical channel models, which would be deviated from realistic channels. In this paper, we develop and compare a vector Kalman filter (VKF)-based channel predictor and a machine learning (ML)-based channel predictor using the realistic channels from the spatial channel model (SCM), which has been adopted in the 3GPP standard for years. First, we propose a low-complexity mobility estimator based on the spatial average using a large number of antennas in massive MIMO. The mobility estimate can be used to determine the complexity order of developed predictors. The VKF-based channel predictor developed in this paper exploits the autoregressive (AR) parameters estimated from the SCM channels based on the Yule-Walker equations. Then, the ML-based channel predictor using the linear minimum mean square error (LMMSE)-based noise pre-processed data is developed. Numerical results reveal that both channel predictors have substantial gain over the outdated channel in terms of the channel prediction accuracy and data rate. The ML-based predictor has larger overall computational complexity than the VKF-based predictor, but once trained, the operational complexity of ML-based predictor becomes smaller than that of VKF-based predictor.