 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributable Watermarking of Speech Generative Models
Feb 17, 2022

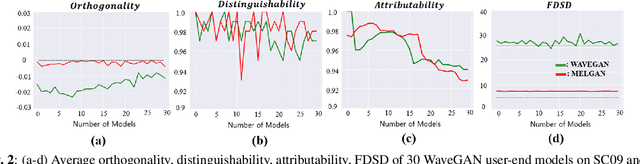

Generative models are now capable of synthesizing images, speeches, and videos that are hardly distinguishable from authentic contents. Such capabilities cause concerns such as malicious impersonation and IP theft. This paper investigates a solution for model attribution, i.e., the classification of synthetic contents by their source models via watermarks embedded in the contents. Building on past success of model attribution in the image domain, we discuss algorithmic improvements for generating user-end speech models that empirically achieve high attribution accuracy, while maintaining high generation quality. We show the trade off between attributability and generation quality under a variety of attacks on generated speech signals attempting to remove the watermarks, and the feasibility of learning robust watermarks against these attacks.