 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Heaviside Function Approximation for Neural Network Binary Classification
Sep 02, 2020
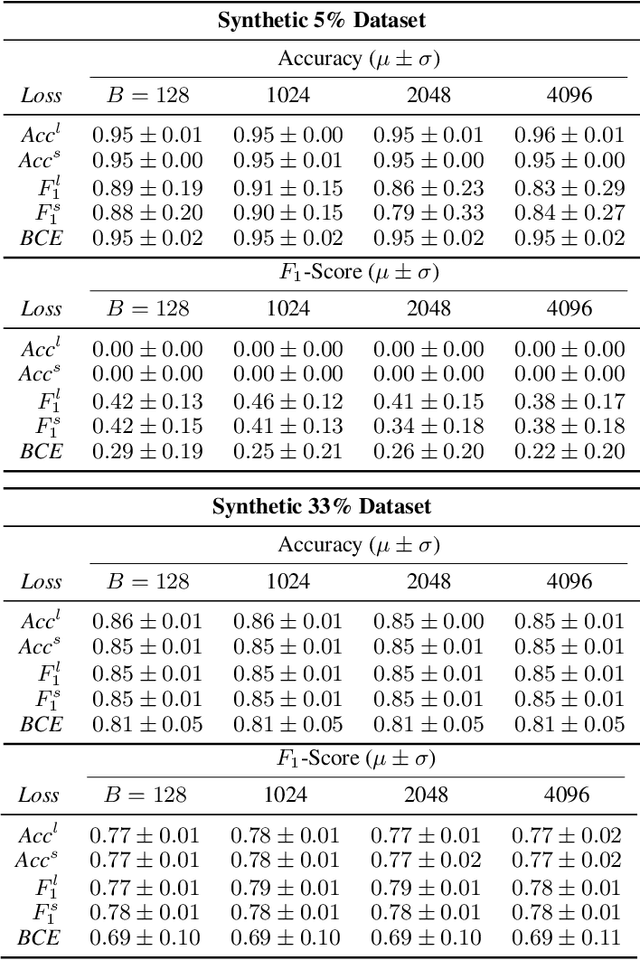
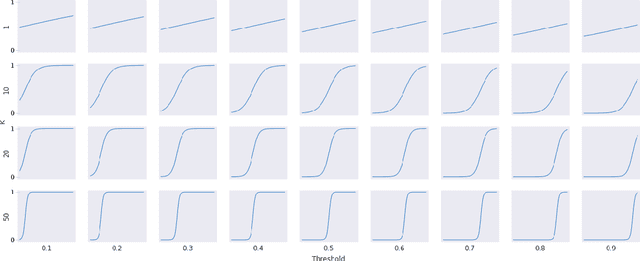
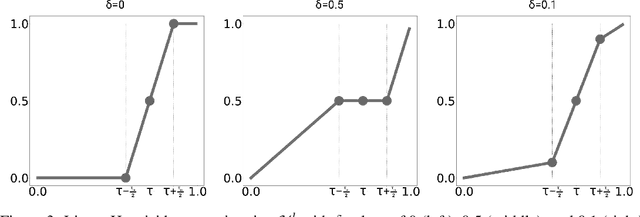
Neural network binary classifiers are often evaluated on metrics like accuracy and $F_1$-Score, which are based on confusion matrix values (True Positives, False Positives, False Negatives, and True Negatives). However, these classifiers are commonly trained with a different loss, e.g. log loss. While it is preferable to perform training on the same loss as the evaluation metric, this is difficult in the case of confusion matrix based metrics because set membership is a step function without a derivative useful for backpropagation. To address this challenge, we propose an approximation of the step function that adheres to the properties necessary for effective training of binary networks using confusion matrix based metrics. This approach allows for end-to-end training of binary deep neural classifiers via batch gradient descent. We demonstrate the flexibility of this approach in several applications with varying levels of class imbalance. We also demonstrate how the approximation allows balancing between precision and recall in the appropriate ratio for the task at hand.