 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepRead: Document Structure-Aware Reasoning to Enhance Agentic Search
Feb 04, 2026With the rapid progress of tool-using and agentic large language models (LLMs), Retrieval-Augmented Generation (RAG) is evolving from one-shot, passive retrieval into multi-turn, decision-driven evidence acquisition. Despite strong results in open-domain settings, existing agentic search frameworks commonly treat long documents as flat collections of chunks, underutilizing document-native priors such as hierarchical organization and sequential discourse structure. We introduce DeepRead, a structure-aware, multi-turn document reasoning agent that explicitly operationalizes these priors for long-document question answering. DeepRead leverages LLM-based OCR model to convert PDFs into structured Markdown that preserves headings and paragraph boundaries. It then indexes documents at the paragraph level and assigns each paragraph a coordinate-style metadata key encoding its section identity and in-section order. Building on this representation, DeepRead equips the LLM with two complementary tools: a Retrieve tool that localizes relevant paragraphs while exposing their structural coordinates (with lightweight scanning context), and a ReadSection tool that enables contiguous, order-preserving reading within a specified section and paragraph range. Our experiments demonstrate that DeepRead achieves significant improvements over Search-o1-style agentic search in document question answering. The synergistic effect between retrieval and reading tools is also validated. Our fine-grained behavioral analysis reveals a reading and reasoning paradigm resembling human-like ``locate then read'' behavior.
Reasoning Pattern Matters: Learning to Reason without Human Rationales
Oct 14, 2025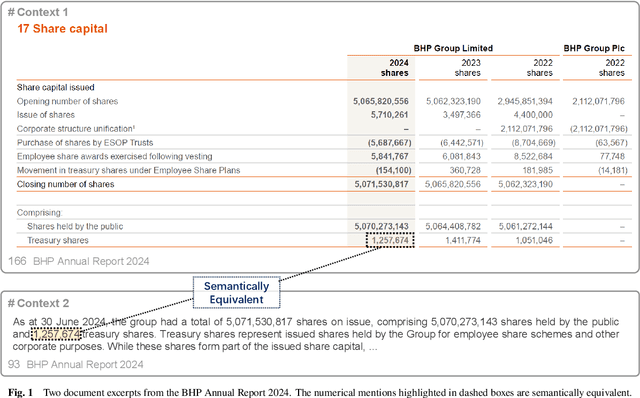
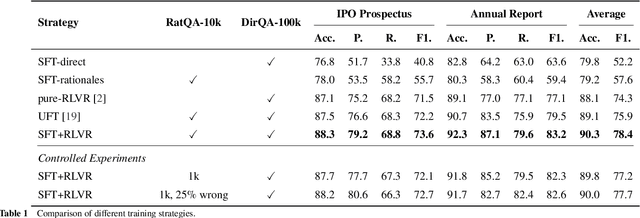
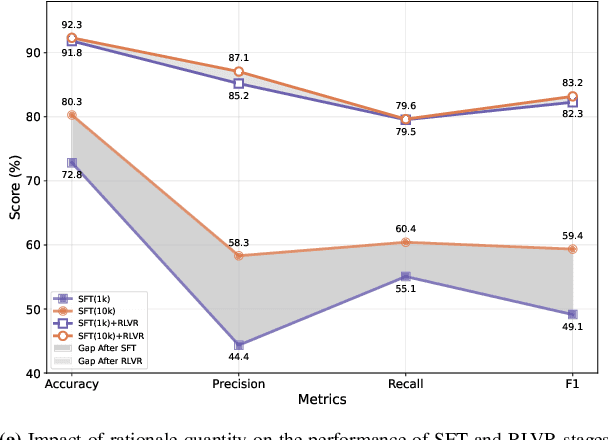
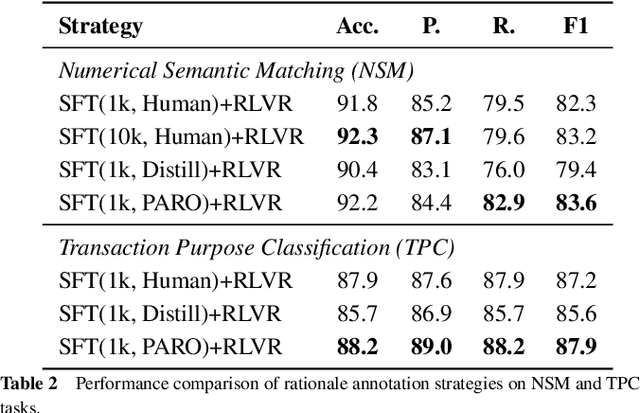
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities under the widely adopted SFT+RLVR paradigm, which first performs Supervised Fine-Tuning (SFT) on human-annotated reasoning trajectories (rationales) to establish initial reasoning behaviors, then applies Reinforcement Learning with Verifiable Rewards (RLVR) to optimize the model using verifiable signals without golden rationales. However, annotating high-quality rationales for the SFT stage remains prohibitively expensive. This paper investigates when and how rationale annotation costs can be substantially reduced without compromising reasoning performance. We identify a broad class of problems, termed patterned reasoning tasks, where reasoning follows a fixed, procedural strategy consistent across instances. Although instances vary in content such as domain knowledge, factual information, or numeric values, the solution derives from applying a shared reasoning pattern. We argue that the success of SFT+RLVR on such tasks primarily stems from its ability to enable models to internalize these reasoning patterns. Using numerical semantic matching as a representative task, we provide both causal and behavioral evidence showing that reasoning patterns rather than the quantity or quality of rationales are the key determinant of performance. Building on these insights, we propose Pattern-Aware LLMs as Rationale AnnOtators (PARO), a simple yet effective framework that enables LLMs to generate rationales aligned with task-specific reasoning patterns without requiring human rationale annotations. Experiments show that PARO-generated rationales achieve comparable SFT+RLVR performance to human rationales that are 10 times larger. These results suggest that large-scale human rationale annotations can be replaced with LLM-based automatic annotations requiring only limited human supervision over reasoning patterns.
Document-Level Tabular Numerical Cross-Checking: A Coarse-to-Fine Approach
Jun 16, 2025Numerical consistency across tables in disclosure documents is critical for ensuring accuracy, maintaining credibility, and avoiding reputational and economic risks. Automated tabular numerical cross-checking presents two significant challenges: (C1) managing the combinatorial explosion of candidate instances at the document level and (C2) comprehending multi-faceted numerical semantics. Previous research typically depends on heuristic-based filtering or simplified context extraction, often struggling to balance performance and efficiency. Recently, large language models (LLMs) have demonstrated remarkable contextual understanding capabilities that helps address C2 at the instance level, yet they remain hampered by computational inefficiency (C1) and limited domain expertise. This paper introduces CoFiTCheck, a novel LLM-based coarse-to-fine framework that addresses these challenges through two sequential stages: embedding-based filtering and discriminative classification. The embedding-based filtering stage introduces an instructional parallel encoding method to efficiently represent all numerical mentions in a table with LLMs, as well as a decoupled InfoNCE objective to mitigate the isolated mention problem. The discriminative classification stage employs a specialized LLM for fine-grained analysis of the remaining candidate pairs. This stage is further enhanced by our crosstable numerical alignment pretraining paradigm, which leverages weak supervision from cross-table numerical equality relationships to enrich task-specific priors without requiring manual annotation. Comprehensive evaluation across three types of real-world disclosure documents demonstrates that CoFiTCheck significantly outperforms previous methods while maintaining practical efficiency.
Attention with Dependency Parsing Augmentation for Fine-Grained Attribution
Dec 16, 2024To assist humans in efficiently validating RAG-generated content, developing a fine-grained attribution mechanism that provides supporting evidence from retrieved documents for every answer span is essential. Existing fine-grained attribution methods rely on model-internal similarity metrics between responses and documents, such as saliency scores and hidden state similarity. However, these approaches suffer from either high computational complexity or coarse-grained representations. Additionally, a common problem shared by the previous works is their reliance on decoder-only Transformers, limiting their ability to incorporate contextual information after the target span. To address the above problems, we propose two techniques applicable to all model-internals-based methods. First, we aggregate token-wise evidence through set union operations, preserving the granularity of representations. Second, we enhance the attributor by integrating dependency parsing to enrich the semantic completeness of target spans. For practical implementation, our approach employs attention weights as the similarity metric. Experimental results demonstrate that the proposed method consistently outperforms all prior works.
Uncovering Limitations of Large Language Models in Information Seeking from Tables
Jun 06, 2024Tables are recognized for their high information density and widespread usage, serving as essential sources of information. Seeking information from tables (TIS) is a crucial capability for Large Language Models (LLMs), serving as the foundation of knowledge-based Q&A systems. However, this field presently suffers from an absence of thorough and reliable evaluation. This paper introduces a more reliable benchmark for Table Information Seeking (TabIS). To avoid the unreliable evaluation caused by text similarity-based metrics, TabIS adopts a single-choice question format (with two options per question) instead of a text generation format. We establish an effective pipeline for generating options, ensuring their difficulty and quality. Experiments conducted on 12 LLMs reveal that while the performance of GPT-4-turbo is marginally satisfactory, both other proprietary and open-source models perform inadequately. Further analysis shows that LLMs exhibit a poor understanding of table structures, and struggle to balance between TIS performance and robustness against pseudo-relevant tables (common in retrieval-augmented systems). These findings uncover the limitations and potential challenges of LLMs in seeking information from tables. We release our data and code to facilitate further research in this field.
Guideline Learning for In-context Information Extraction
Oct 21, 2023Large language models (LLMs) can perform a new task by merely conditioning on task instructions and a few input-output examples, without optimizing any parameters. This is called In-Context Learning (ICL). In-context Information Extraction (IE) has recently garnered attention in the research community. However, the performance of In-context IE generally lags behind the state-of-the-art supervised expert models. We highlight a key reason for this shortfall: underspecified task description. The limited-length context struggles to thoroughly express the intricate IE task instructions and various edge cases, leading to misalignment in task comprehension with humans. In this paper, we propose a Guideline Learning (GL) framework for In-context IE which reflectively learns and follows guidelines. During the learning phrase, GL automatically synthesizes a set of guidelines based on a few error cases, and during inference, GL retrieves helpful guidelines for better ICL. Moreover, we propose a self-consistency-based active learning method to enhance the efficiency of GL. Experiments on event extraction and relation extraction show that GL can significantly improve the performance of in-context IE.
Extracting Variable-Depth Logical Document Hierarchy from Long Documents: Method, Evaluation, and Application
May 14, 2021
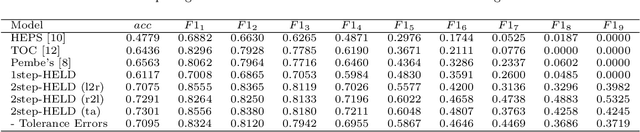
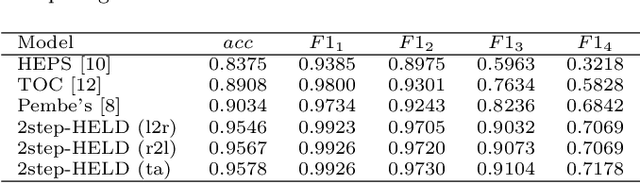
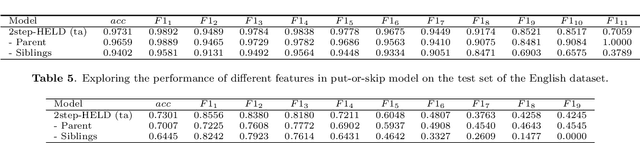
In this paper, we study the problem of extracting variable-depth "logical document hierarchy" from long documents, namely organizing the recognized "physical document objects" into hierarchical structures. The discovery of logical document hierarchy is the vital step to support many downstream applications. However, long documents, containing hundreds or even thousands of pages and variable-depth hierarchy, challenge the existing methods. To address these challenges, we develop a framework, namely Hierarchy Extraction from Long Document (HELD), where we "sequentially" insert each physical object at the proper on of the current tree. Determining whether each possible position is proper or not can be formulated as a binary classification problem. To further improve its effectiveness and efficiency, we study the design variants in HELD, including traversal orders of the insertion positions, heading extraction explicitly or implicitly, tolerance to insertion errors in predecessor steps, and so on. The empirical experiments based on thousands of long documents from Chinese, English financial market and English scientific publication show that the HELD model with the "root-to-leaf" traversal order and explicit heading extraction is the best choice to achieve the tradeoff between effectiveness and efficiency with the accuracy of 0.9726, 0.7291 and 0.9578 in Chinese financial, English financial and arXiv datasets, respectively. Finally, we show that logical document hierarchy can be employed to significantly improve the performance of the downstream passage retrieval task. In summary, we conduct a systematic study on this task in terms of methods, evaluations, and applications.
* 23 pages, 10 figures, Journal of computer science and technology