 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtrial Fibrillation Detection Using RR-Intervals for Application in Photoplethysmographs
Feb 13, 2023



Atrial Fibrillation is a common form of irregular heart rhythm that can be very dangerous. Our primary goal is to analyze Atrial Fibrillation data within ECGs to develop a model based only on RR-Intervals, or the length between heart-beats, to create a real time classification model for Atrial Fibrillation to be implemented in common heart-rate monitors on the market today. Physionet's MIT-BIH Atrial Fibrillation Database \cite{goldberger2000physiobank} and 2017 Challenge Database \cite{clifford2017af} were used to identify patterns of Atrial Fibrillation and test classification models on. These two datasets are very different. The MIT-BIH database contains long samples taken with a medical grade device, which is not useful for simulating a consumer device, but is useful for Atrial Fibrillation pattern detection. The 2017 Challenge database includes short ($<60sec$) samples taken with a portable device and reveals many of the challenges of Atrial Fibrillation classification in a real-time device. We developed multiple SVM models with three sets of extracted features as predictor variables which gave us moderately high accuracies with low computational intensity. With robust filtering techniques already applied in many Photoplethysmograph-based consumer heart-rate monitors, this method can be used to develop a reliable real time model for Atrial Fibrillation detection in consumer-grade heart-rate monitors.
A Comparison Study on Nonlinear Dimension Reduction Methods with Kernel Variations: Visualization, Optimization and Classification
Oct 04, 2019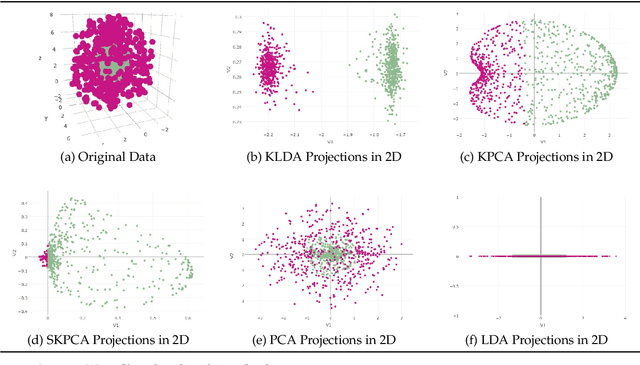
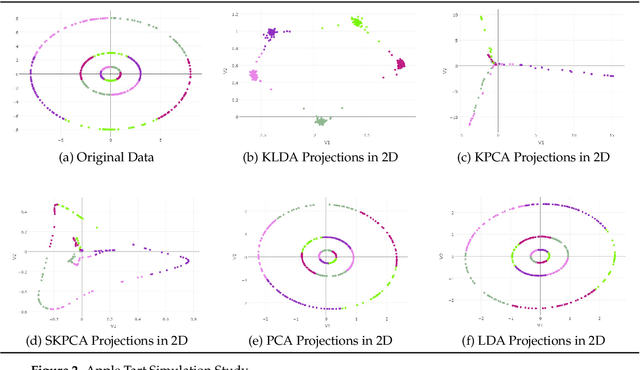

Because of high dimensionality, correlation among covariates, and noise contained in data, dimension reduction (DR) techniques are often employed to the application of machine learning algorithms. Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and their kernel variants (KPCA, KLDA) are among the most popular DR methods. Recently, Supervised Kernel Principal Component Analysis (SKPCA) has been shown as another successful alternative. In this paper, brief reviews of these popular techniques are presented first. We then conduct a comparative performance study based on three simulated datasets, after which the performance of the techniques are evaluated through application to a pattern recognition problem in face image analysis. The gender classification problem is considered on MORPH-II and FG-NET, two popular longitudinal face aging databases. Several feature extraction methods are used, including biologically-inspired features (BIF), local binary patterns (LBP), histogram of oriented gradients (HOG), and the Active Appearance Model (AAM). After applications of DR methods, a linear support vector machine (SVM) is deployed with gender classification accuracy rates exceeding 95% on MORPH-II, competitive with benchmark results. A parallel computational approach is also proposed, attaining faster processing speeds and similar recognition rates on MORPH-II. Our computational approach can be applied to practical gender classification systems and generalized to other face analysis tasks, such as race classification and age prediction.
Image Pre-processing Using OpenCV Library on MORPH-II Face Database
Nov 16, 2018



This paper outlines the steps taken toward pre-processing the 55,134 images of the MORPH-II non-commercial dataset. Following the introduction, section two begins with an overview of each step in the pre-processing pipeline. Section three expands upon each stage of the process and includes details on all calculations made, by providing the OpenCV functionality paired with each step. The last portion of this paper discusses the potential improvements to this pre-processing pipeline that became apparent in retrospect.
Preliminary Studies on a Large Face Database
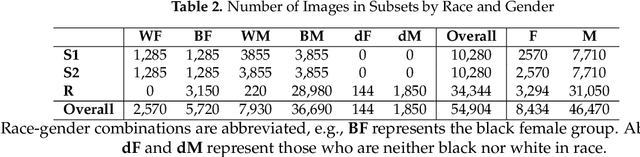
Nov 15, 2018

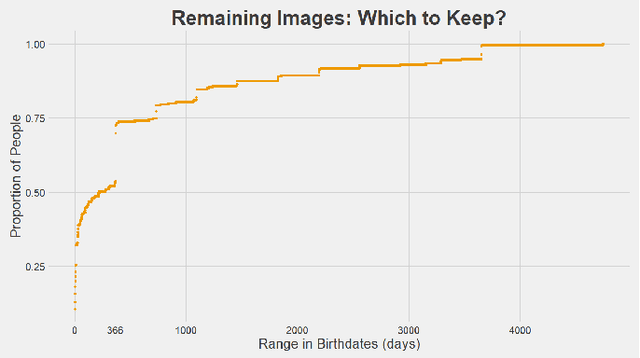
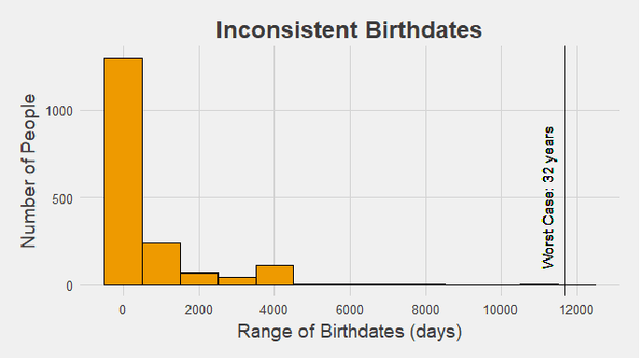
We perform preliminary studies on a large longitudinal face database MORPH-II, which is a benchmark dataset in the field of computer vision and pattern recognition. First, we summarize the inconsistencies in the dataset and introduce the steps and strategy taken for cleaning. The potential implications of these inconsistencies on prior research are introduced. Next, we propose a new automatic subsetting scheme for evaluation protocol. It is intended to overcome the unbalanced racial and gender distributions of MORPH-II, while ensuring independence between training and testing sets. Finally, we contribute a novel global framework for age estimation that utilizes posterior probabilities from the race classification step to compute a racecomposite age estimate. Preliminary experimental results on MORPH-II are presented.
Gender Effect on Face Recognition for a Large Longitudinal Database
Nov 08, 2018
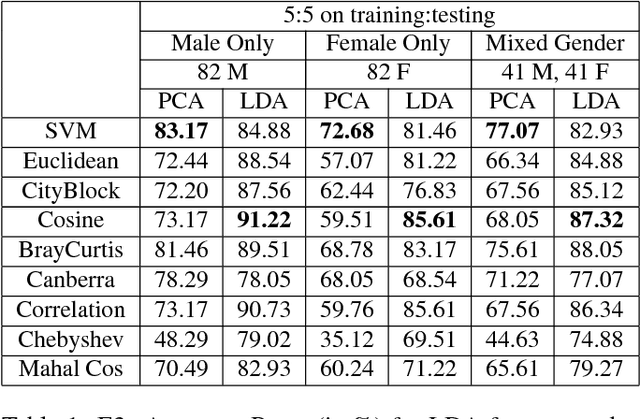
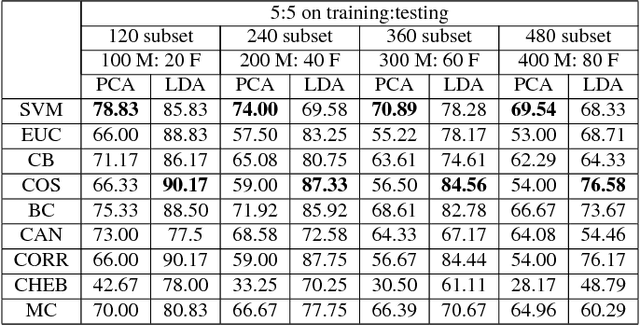

Aging or gender variation can affect the face recognition performance dramatically. While most of the face recognition studies are focused on the variation of pose, illumination and expression, it is important to consider the influence of gender effect and how to design an effective matching framework. In this paper, we address these problems on a very large longitudinal database MORPH-II which contains 55,134 face images of 13,617 individuals. First, we consider four comprehensive experiments with different combination of gender distribution and subset size, including: 1) equal gender distribution; 2) a large highly unbalanced gender distribution; 3) consider different gender combinations, such as male only, female only, or mixed gender; and 4) the effect of subset size in terms of number of individuals. Second, we consider eight nearest neighbor distance metrics and also Support Vector Machine (SVM) for classifiers and test the effect of different classifiers. Last, we consider different fusion techniques for an effective matching framework to improve the recognition performance.