 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Pre-processing Using OpenCV Library on MORPH-II Face Database
Nov 16, 2018



This paper outlines the steps taken toward pre-processing the 55,134 images of the MORPH-II non-commercial dataset. Following the introduction, section two begins with an overview of each step in the pre-processing pipeline. Section three expands upon each stage of the process and includes details on all calculations made, by providing the OpenCV functionality paired with each step. The last portion of this paper discusses the potential improvements to this pre-processing pipeline that became apparent in retrospect.
Preliminary Studies on a Large Face Database
Nov 15, 2018

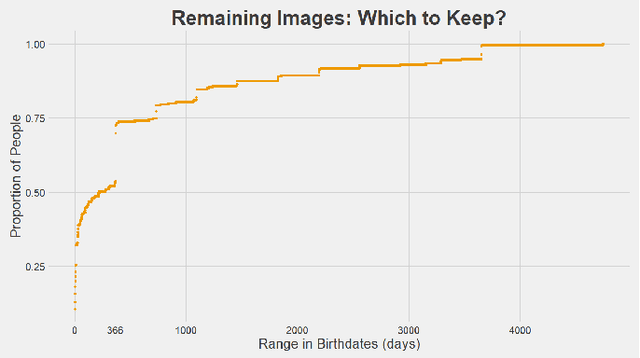
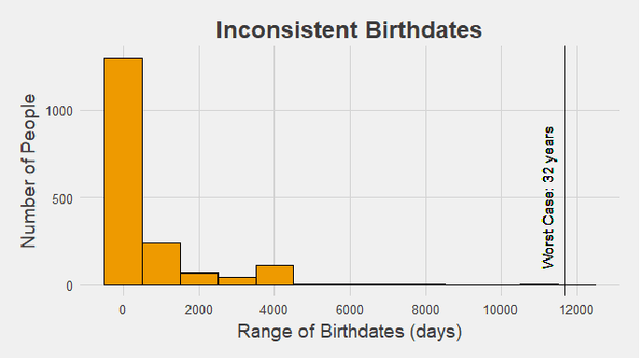
We perform preliminary studies on a large longitudinal face database MORPH-II, which is a benchmark dataset in the field of computer vision and pattern recognition. First, we summarize the inconsistencies in the dataset and introduce the steps and strategy taken for cleaning. The potential implications of these inconsistencies on prior research are introduced. Next, we propose a new automatic subsetting scheme for evaluation protocol. It is intended to overcome the unbalanced racial and gender distributions of MORPH-II, while ensuring independence between training and testing sets. Finally, we contribute a novel global framework for age estimation that utilizes posterior probabilities from the race classification step to compute a racecomposite age estimate. Preliminary experimental results on MORPH-II are presented.