 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025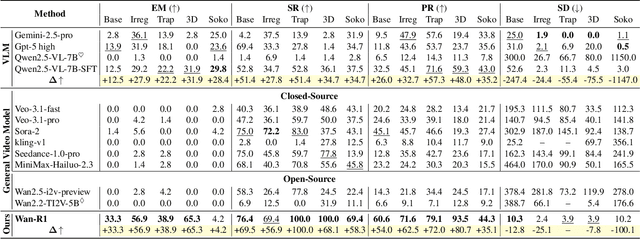

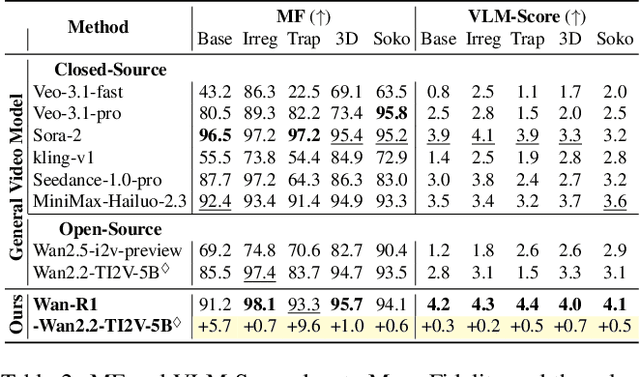
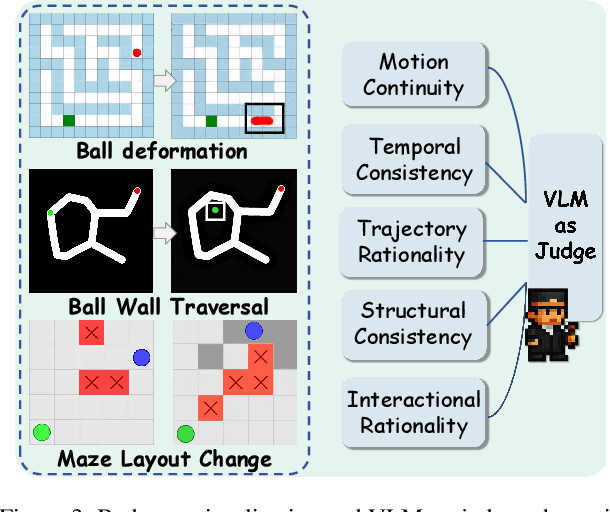
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
Tracking Air Pollution in China: Near Real-Time PM2.5 Retrievals from Multiple Data Sources
Mar 11, 2021
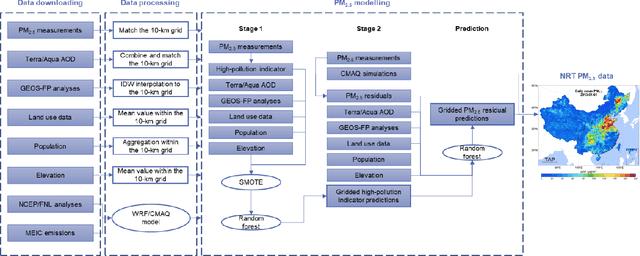

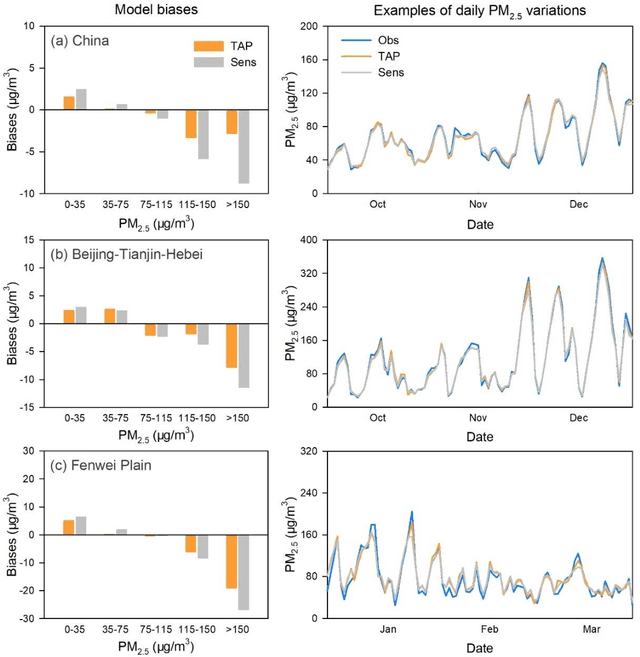
Air pollution has altered the Earth radiation balance, disturbed the ecosystem and increased human morbidity and mortality. Accordingly, a full-coverage high-resolution air pollutant dataset with timely updates and historical long-term records is essential to support both research and environmental management. Here, for the first time, we develop a near real-time air pollutant database known as Tracking Air Pollution in China (TAP, tapdata.org) that combines information from multiple data sources, including ground measurements, satellite retrievals, dynamically updated emission inventories, operational chemical transport model simulations and other ancillary data. Daily full-coverage PM2.5 data at a spatial resolution of 10 km is our first near real-time product. The TAP PM2.5 is estimated based on a two-stage machine learning model coupled with the synthetic minority oversampling technique and a tree-based gap-filling method. Our model has an averaged out-of-bag cross-validation R2 of 0.83 for different years, which is comparable to those of other studies, but improves its performance at high pollution levels and fills the gaps in missing AOD on daily scale. The full coverage and near real-time updates of the daily PM2.5 data allow us to track the day-to-day variations in PM2.5 concentrations over China in a timely manner. The long-term records of PM2.5 data since 2000 will also support policy assessments and health impact studies. The TAP PM2.5 data are publicly available through our website for sharing with the research and policy communities.
Estimates of daily ground-level NO2 concentrations in China based on big data and machine learning approaches
Nov 18, 2020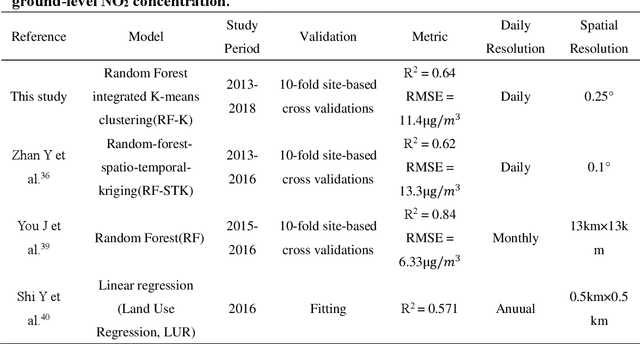
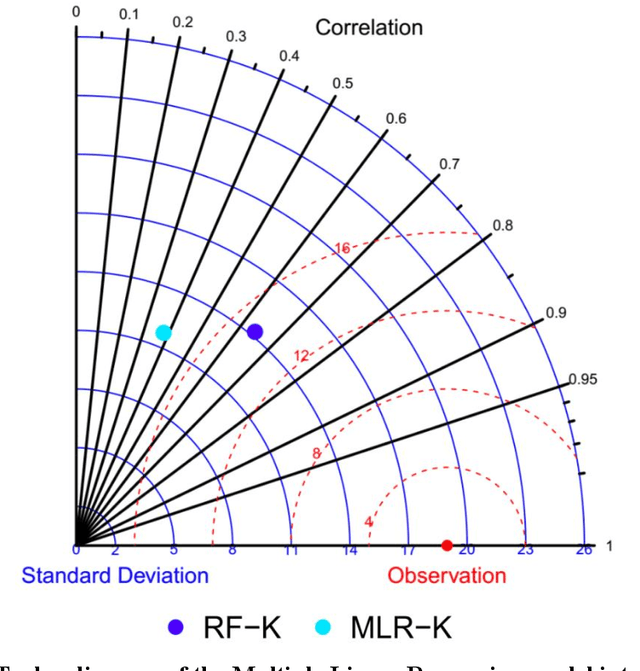
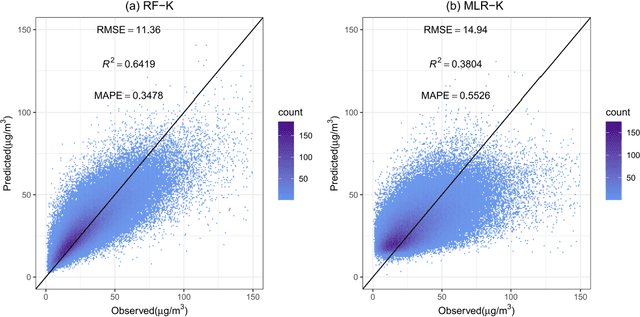
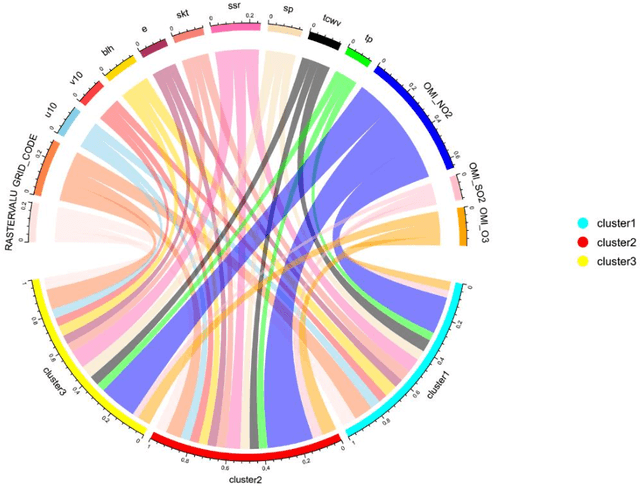
Nitrogen dioxide (NO2) is one of the most important atmospheric pollutants. However, current ground-level NO2 concentration data are lack of either high-resolution coverage or full coverage national wide, due to the poor quality of source data and the computing power of the models. To our knowledge, this study is the first to estimate the ground-level NO2 concentration in China with national coverage as well as relatively high spatiotemporal resolution (0.25 degree; daily intervals) over the newest past 6 years (2013-2018). We advanced a Random Forest model integrated K-means (RF-K) for the estimates with multi-source parameters. Besides meteorological parameters, satellite retrievals parameters, we also, for the first time, introduce socio-economic parameters to assess the impact by human activities. The results show that: (1) the RF-K model we developed shows better prediction performance than other models, with cross-validation R2 = 0.64 (MAPE = 34.78%). (2) The annual average concentration of NO2 in China showed a weak increasing trend . While in the economic zones such as Beijing-Tianjin-Hebei region, Yangtze River Delta, and Pearl River Delta, the NO2 concentration there even decreased or remained unchanged, especially in spring. Our dataset has verified that pollutant controlling targets have been achieved in these areas. With mapping daily nationwide ground-level NO2 concentrations, this study provides timely data with high quality for air quality management for China. We provide a universal model framework to quickly generate a timely national atmospheric pollutants concentration map with a high spatial-temporal resolution, based on improved machine learning methods.