 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Expert System: Large Language Models as Text Classifiers
May 17, 2024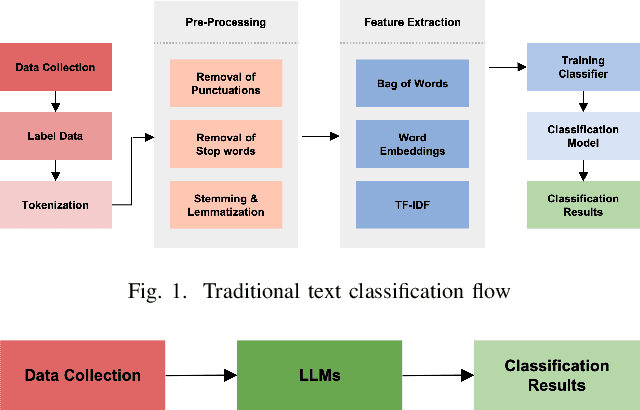
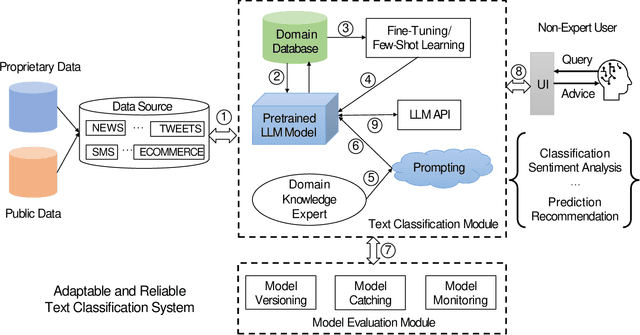

Text classification is a fundamental task in Natural Language Processing (NLP), and the advent of Large Language Models (LLMs) has revolutionized the field. This paper introduces the Smart Expert System, a novel approach that leverages LLMs as text classifiers. The system simplifies the traditional text classification workflow, eliminating the need for extensive preprocessing and domain expertise. The performance of several LLMs, machine learning (ML) algorithms, and neural network (NN) based structures is evaluated on four datasets. Results demonstrate that certain LLMs surpass traditional methods in sentiment analysis, spam SMS detection and multi-label classification. Furthermore, it is shown that the system's performance can be further enhanced through few-shot or fine-tuning strategies, making the fine-tuned model the top performer across all datasets. Source code and datasets are available in this GitHub repository: https://github.com/yeyimilk/llm-zero-shot-classifiers.
Large Language Models Are Zero-Shot Text Classifiers
Dec 02, 2023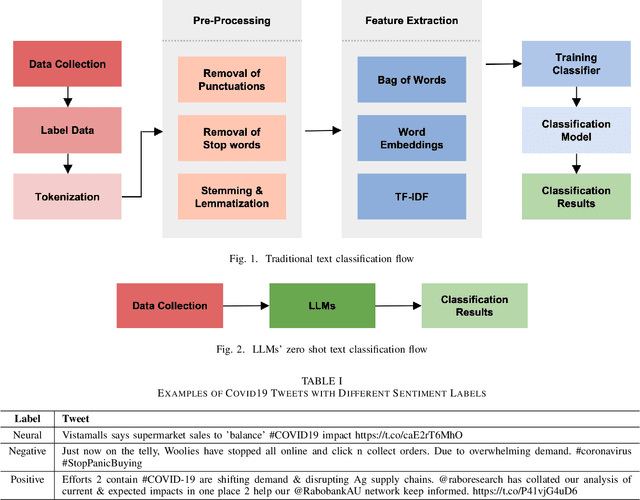
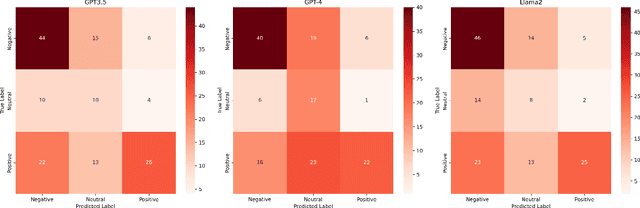

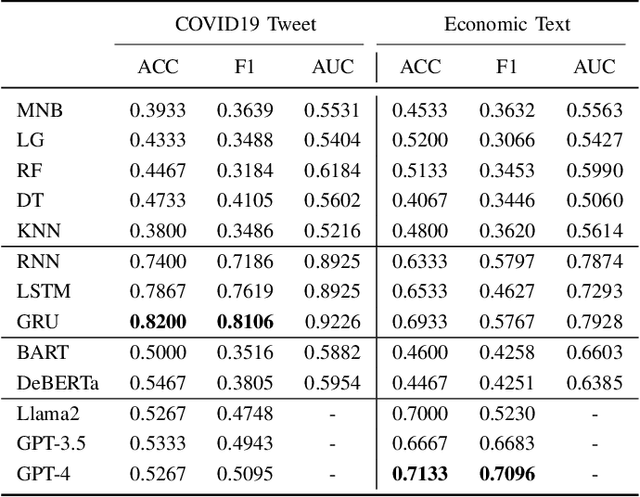
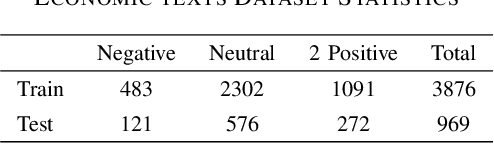
Retrained large language models (LLMs) have become extensively used across various sub-disciplines of natural language processing (NLP). In NLP, text classification problems have garnered considerable focus, but still faced with some limitations related to expensive computational cost, time consumption, and robust performance to unseen classes. With the proposal of chain of thought prompting (CoT), LLMs can be implemented using zero-shot learning (ZSL) with the step by step reasoning prompts, instead of conventional question and answer formats. The zero-shot LLMs in the text classification problems can alleviate these limitations by directly utilizing pretrained models to predict both seen and unseen classes. Our research primarily validates the capability of GPT models in text classification. We focus on effectively utilizing prompt strategies to various text classification scenarios. Besides, we compare the performance of zero shot LLMs with other state of the art text classification methods, including traditional machine learning methods, deep learning methods, and ZSL methods. Experimental results demonstrate that the performance of LLMs underscores their effectiveness as zero-shot text classifiers in three of the four datasets analyzed. The proficiency is especially advantageous for small businesses or teams that may not have extensive knowledge in text classification.
Counting Manatee Aggregations using Deep Neural Networks and Anisotropic Gaussian Kernel
Nov 04, 2023Manatees are aquatic mammals with voracious appetites. They rely on sea grass as the main food source, and often spend up to eight hours a day grazing. They move slow and frequently stay in group (i.e. aggregations) in shallow water to search for food, making them vulnerable to environment change and other risks. Accurate counting manatee aggregations within a region is not only biologically meaningful in observing their habit, but also crucial for designing safety rules for human boaters, divers, etc., as well as scheduling nursing, intervention, and other plans. In this paper, we propose a deep learning based crowd counting approach to automatically count number of manatees within a region, by using low quality images as input. Because manatees have unique shape and they often stay in shallow water in groups, water surface reflection, occlusion, camouflage etc. making it difficult to accurately count manatee numbers. To address the challenges, we propose to use Anisotropic Gaussian Kernel (AGK), with tunable rotation and variances, to ensure that density functions can maximally capture shapes of individual manatees in different aggregations. After that, we apply AGK kernel to different types of deep neural networks primarily designed for crowd counting, including VGG, SANet, Congested Scene Recognition network (CSRNet), MARUNet etc. to learn manatee densities and calculate number of manatees in the scene. By using generic low quality images extracted from surveillance videos, our experiment results and comparison show that AGK kernel based manatee counting achieves minimum Mean Absolute Error (MAE) and Root Mean Square Error (RMSE). The proposed method works particularly well for counting manatee aggregations in environments with complex background.