 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACORT: A Compact Object Relation Transformer for Parameter Efficient Image Captioning
Feb 11, 2022
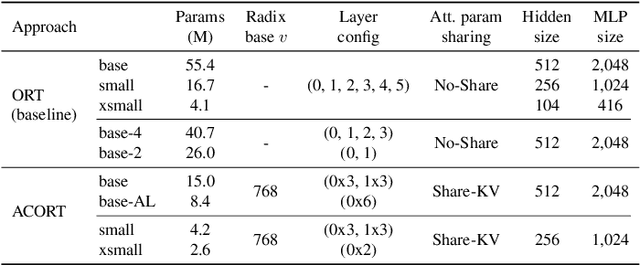

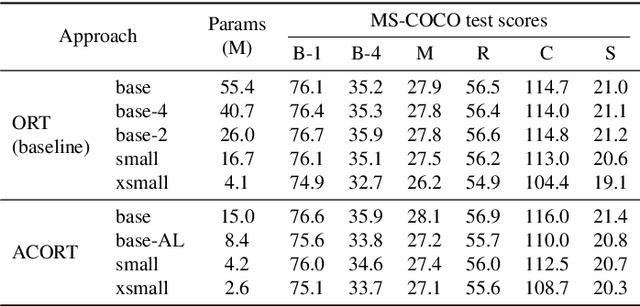
Recent research that applies Transformer-based architectures to image captioning has resulted in state-of-the-art image captioning performance, capitalising on the success of Transformers on natural language tasks. Unfortunately, though these models work well, one major flaw is their large model sizes. To this end, we present three parameter reduction methods for image captioning Transformers: Radix Encoding, cross-layer parameter sharing, and attention parameter sharing. By combining these methods, our proposed ACORT models have 3.7x to 21.6x fewer parameters than the baseline model without compromising test performance. Results on the MS-COCO dataset demonstrate that our ACORT models are competitive against baselines and SOTA approaches, with CIDEr score >=126. Finally, we present qualitative results and ablation studies to demonstrate the efficacy of the proposed changes further. Code and pre-trained models are publicly available at https://github.com/jiahuei/sparse-image-captioning.
Phrase-based Image Captioning with Hierarchical LSTM Model
Nov 11, 2017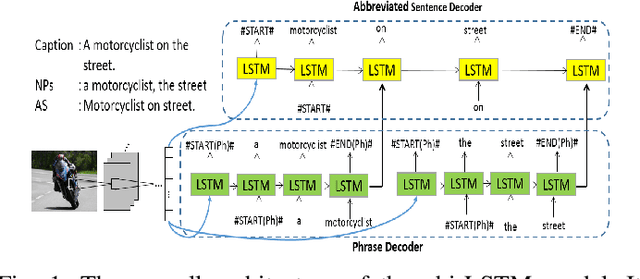



Automatic generation of caption to describe the content of an image has been gaining a lot of research interests recently, where most of the existing works treat the image caption as pure sequential data. Natural language, however possess a temporal hierarchy structure, with complex dependencies between each subsequence. In this paper, we propose a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model to generate image description. In contrast to the conventional solutions that generate caption in a pure sequential manner, our proposed model decodes image caption from phrase to sentence. It consists of a phrase decoder at the bottom hierarchy to decode noun phrases of variable length, and an abbreviated sentence decoder at the upper hierarchy to decode an abbreviated form of the image description. A complete image caption is formed by combining the generated phrases with sentence during the inference stage. Empirically, our proposed model shows a better or competitive result on the Flickr8k, Flickr30k and MS-COCO datasets in comparison to the state-of-the art models. We also show that our proposed model is able to generate more novel captions (not seen in the training data) which are richer in word contents in all these three datasets.
phi-LSTM: A Phrase-based Hierarchical LSTM Model for Image Captioning
Oct 26, 2017



A picture is worth a thousand words. Not until recently, however, we noticed some success stories in understanding of visual scenes: a model that is able to detect/name objects, describe their attributes, and recognize their relationships/interactions. In this paper, we propose a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model to generate image description. The proposed model encodes sentence as a sequence of combination of phrases and words, instead of a sequence of words alone as in those conventional solutions. The two levels of this model are dedicated to i) learn to generate image relevant noun phrases, and ii) produce appropriate image description from the phrases and other words in the corpus. Adopting a convolutional neural network to learn image features and the LSTM to learn the word sequence in a sentence, the proposed model has shown better or competitive results in comparison to the state-of-the-art models on Flickr8k and Flickr30k datasets.