 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowMamba: State-Space Model with Boundary-Region Selective Scan for Shadow Removal
Nov 05, 2024



Image shadow removal is a typical low-level vision problem, where the presence of shadows leads to abrupt changes in brightness in certain regions, affecting the accuracy of upstream tasks. Current shadow removal methods still face challenges such as residual boundary artifacts, and capturing feature information at shadow boundaries is crucial for removing shadows and eliminating residual boundary artifacts. Recently, Mamba has achieved remarkable success in computer vision by globally modeling long-sequence information with linear complexity. However, when applied to image shadow removal, the original Mamba scanning method overlooks the semantic continuity of shadow boundaries as well as the continuity of semantics within the same region. Based on the unique characteristics of shadow images, this paper proposes a novel selective scanning method called boundary-region selective scanning. This method scans boundary regions, shadow regions, and non-shadow regions independently, bringing pixels of the same region type closer together in the long sequence, especially focusing on the local information at the boundaries, which is crucial for shadow removal. This method combines with global scanning and channel scanning to jointly accomplish the shadow removal. We name our model ShadowMamba, the first Mamba-based model for shadow removal. Extensive experimental results show that our method outperforms current state-of-the-art models across most metrics on multiple datasets. The code for ShadowMamba is available at (Code will be released upon acceptance).
ACORT: A Compact Object Relation Transformer for Parameter Efficient Image Captioning
Feb 11, 2022
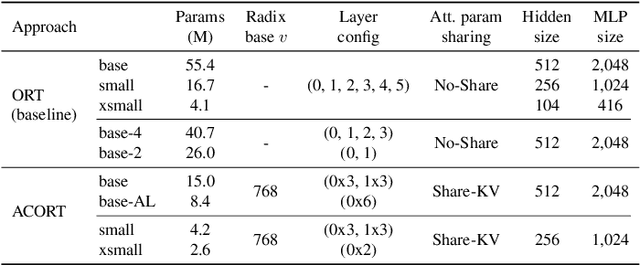

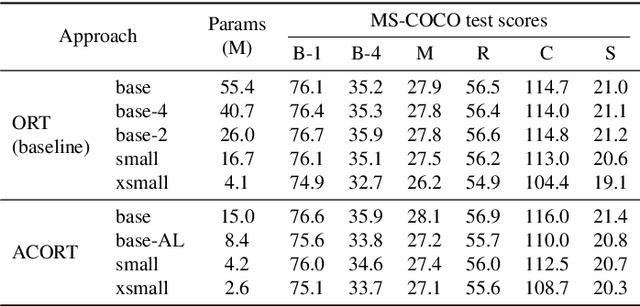
Recent research that applies Transformer-based architectures to image captioning has resulted in state-of-the-art image captioning performance, capitalising on the success of Transformers on natural language tasks. Unfortunately, though these models work well, one major flaw is their large model sizes. To this end, we present three parameter reduction methods for image captioning Transformers: Radix Encoding, cross-layer parameter sharing, and attention parameter sharing. By combining these methods, our proposed ACORT models have 3.7x to 21.6x fewer parameters than the baseline model without compromising test performance. Results on the MS-COCO dataset demonstrate that our ACORT models are competitive against baselines and SOTA approaches, with CIDEr score >=126. Finally, we present qualitative results and ablation studies to demonstrate the efficacy of the proposed changes further. Code and pre-trained models are publicly available at https://github.com/jiahuei/sparse-image-captioning.
End-to-End Supermask Pruning: Learning to Prune Image Captioning Models
Oct 07, 2021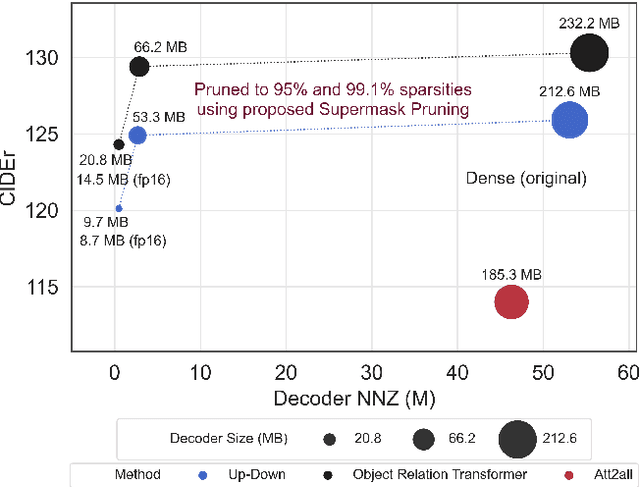
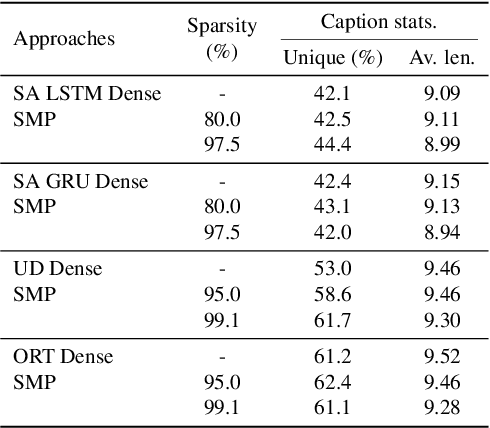
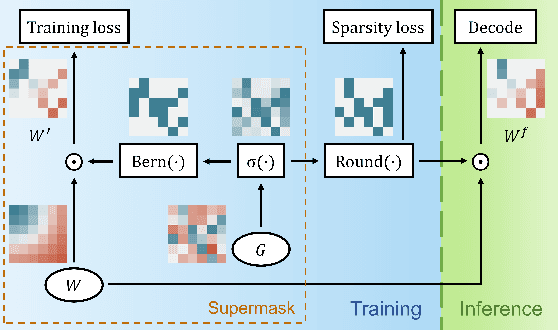

With the advancement of deep models, research work on image captioning has led to a remarkable gain in raw performance over the last decade, along with increasing model complexity and computational cost. However, surprisingly works on compression of deep networks for image captioning task has received little to no attention. For the first time in image captioning research, we provide an extensive comparison of various unstructured weight pruning methods on three different popular image captioning architectures, namely Soft-Attention, Up-Down and Object Relation Transformer. Following this, we propose a novel end-to-end weight pruning method that performs gradual sparsification based on weight sensitivity to the training loss. The pruning schemes are then extended with encoder pruning, where we show that conducting both decoder pruning and training simultaneously prior to the encoder pruning provides good overall performance. Empirically, we show that an 80% to 95% sparse network (up to 75% reduction in model size) can either match or outperform its dense counterpart. The code and pre-trained models for Up-Down and Object Relation Transformer that are capable of achieving CIDEr scores >120 on the MS-COCO dataset but with only 8.7 MB and 14.5 MB in model size (size reduction of 96% and 94% respectively against dense versions) are publicly available at https://github.com/jiahuei/sparse-image-captioning.
Image Captioning with Sparse Recurrent Neural Network
Aug 28, 2019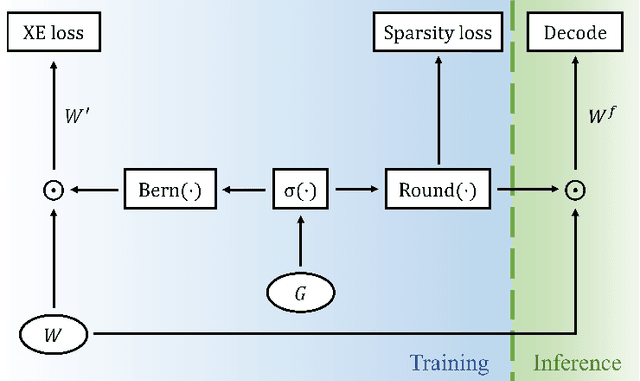



Recurrent Neural Network (RNN) has been deployed as the de facto model to tackle a wide variety of language generation problems and achieved state-of-the-art (SOTA) performance. However despite its impressive results, the large number of parameters in the RNN model makes deployment in mobile and embedded devices infeasible. Driven by this problem, many works have proposed a number of pruning methods to reduce the sizes of the RNN model. In this work, we propose an end-to-end pruning method for image captioning models equipped with visual attention. Our proposed method is able to achieve sparsity levels up to 97.5% without significant performance loss relative to the baseline (around 1% loss at 40x compression of GRU model). Our method is also simple to use and tune, facilitating faster development times for neural network practitioners. We perform extensive experiments on the popular MS-COCO dataset in order to empirically validate the efficacy of our proposed method.
COMIC: Towards A Compact Image Captioning Model with Attention
Mar 16, 2019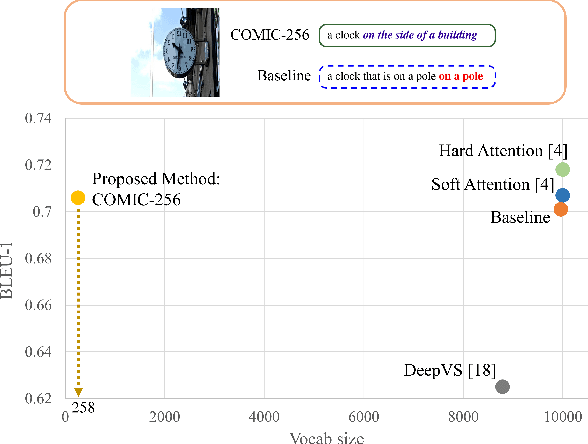



Recent works in image captioning have shown very promising raw performance. However, we realize that most of these encoder-decoder style networks with attention do not scale naturally to large vocabulary size, making them difficult to be deployed on embedded system with limited hardware resources. This is because the size of word and output embedding matrices grow proportionally with the size of vocabulary, adversely affecting the compactness of these networks. To address this limitation, this paper introduces a brand new idea in the domain of image captioning. That is, we tackle the problem of compactness of image captioning models which is hitherto unexplored. We showed that, our proposed model, named COMIC for COMpact Image Captioning, achieves comparable results in five common evaluation metrics with state-of-the-art approaches on both MS-COCO and InstaPIC-1.1M datasets despite having an embedding vocabulary size that is 39x - 99x smaller