 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Rate of First Order Algorithms for Entropic Optimal Transport
Jan 23, 2023This paper improves the state-of-the-art rate of a first-order algorithm for solving entropy regularized optimal transport. The resulting rate for approximating the optimal transport (OT) has been improved from $\widetilde{{O}}({n^{2.5}}/{\epsilon})$ to $\widetilde{{O}}({n^2}/{\epsilon})$, where $n$ is the problem size and $\epsilon$ is the accuracy level. In particular, we propose an accelerated primal-dual stochastic mirror descent algorithm with variance reduction. Such special design helps us improve the rate compared to other accelerated primal-dual algorithms. We further propose a batch version of our stochastic algorithm, which improves the computational performance through parallel computing. To compare, we prove that the computational complexity of the Stochastic Sinkhorn algorithm is $\widetilde{{O}}({n^2}/{\epsilon^2})$, which is slower than our accelerated primal-dual stochastic mirror algorithm. Experiments are done using synthetic and real data, and the results match our theoretical rates. Our algorithm may inspire more research to develop accelerated primal-dual algorithms that have rate $\widetilde{{O}}({n^2}/{\epsilon})$ for solving OT.
Covariance Estimators for the ROOT-SGD Algorithm in Online Learning
Dec 02, 2022



Online learning naturally arises in many statistical and machine learning problems. The most widely used methods in online learning are stochastic first-order algorithms. Among this family of algorithms, there is a recently developed algorithm, Recursive One-Over-T SGD (ROOT-SGD). ROOT-SGD is advantageous in that it converges at a non-asymptotically fast rate, and its estimator further converges to a normal distribution. However, this normal distribution has unknown asymptotic covariance; thus cannot be directly applied to measure the uncertainty. To fill this gap, we develop two estimators for the asymptotic covariance of ROOT-SGD. Our covariance estimators are useful for statistical inference in ROOT-SGD. Our first estimator adopts the idea of plug-in. For each unknown component in the formula of the asymptotic covariance, we substitute it with its empirical counterpart. The plug-in estimator converges at the rate $\mathcal{O}(1/\sqrt{t})$, where $t$ is the sample size. Despite its quick convergence, the plug-in estimator has the limitation that it relies on the Hessian of the loss function, which might be unavailable in some cases. Our second estimator is a Hessian-free estimator that overcomes the aforementioned limitation. The Hessian-free estimator uses the random-scaling technique, and we show that it is an asymptotically consistent estimator of the true covariance.
Solving a Special Type of Optimal Transport Problem by a Modified Hungarian Algorithm
Oct 29, 2022We observe that computing empirical Wasserstein distance in the independence test is an optimal transport (OT) problem with a special structure. This observation inspires us to study a special type of OT problem and propose a modified Hungarian algorithm to solve it exactly. For an OT problem between marginals with $m$ and $n$ atoms ($m\geq n$), the computational complexity of the proposed algorithm is $O(m^2n)$. Computing the empirical Wasserstein distance in the independence test requires solving this special type of OT problem, where we have $m=n^2$. The associate computational complexity of our algorithm is $O(n^5)$, while the order of applying the classic Hungarian algorithm is $O(n^6)$. Numerical experiments validate our theoretical analysis. Broader applications of the proposed algorithm are discussed at the end.
The Directional Bias Helps Stochastic Gradient Descent to Generalize in Kernel Regression Models
Apr 29, 2022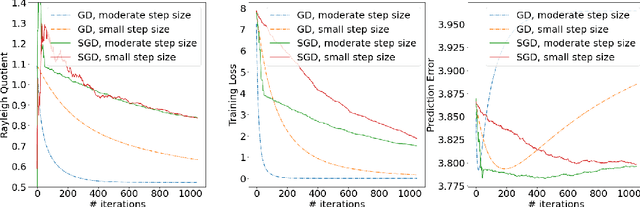
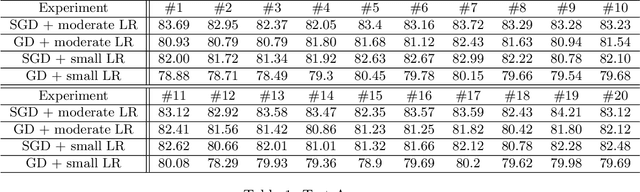
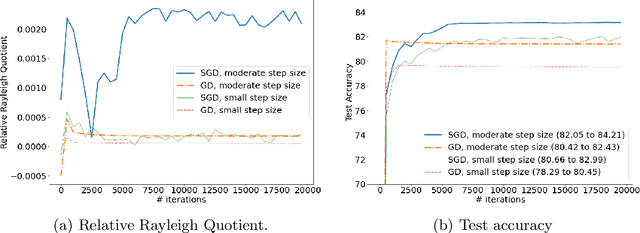

We study the Stochastic Gradient Descent (SGD) algorithm in nonparametric statistics: kernel regression in particular. The directional bias property of SGD, which is known in the linear regression setting, is generalized to the kernel regression. More specifically, we prove that SGD with moderate and annealing step-size converges along the direction of the eigenvector that corresponds to the largest eigenvalue of the Gram matrix. In addition, the Gradient Descent (GD) with a moderate or small step-size converges along the direction that corresponds to the smallest eigenvalue. These facts are referred to as the directional bias properties; they may interpret how an SGD-computed estimator has a potentially smaller generalization error than a GD-computed estimator. The application of our theory is demonstrated by simulation studies and a case study that is based on the FashionMNIST dataset.
Implicit Regularization Properties of Variance Reduced Stochastic Mirror Descent
Apr 29, 2022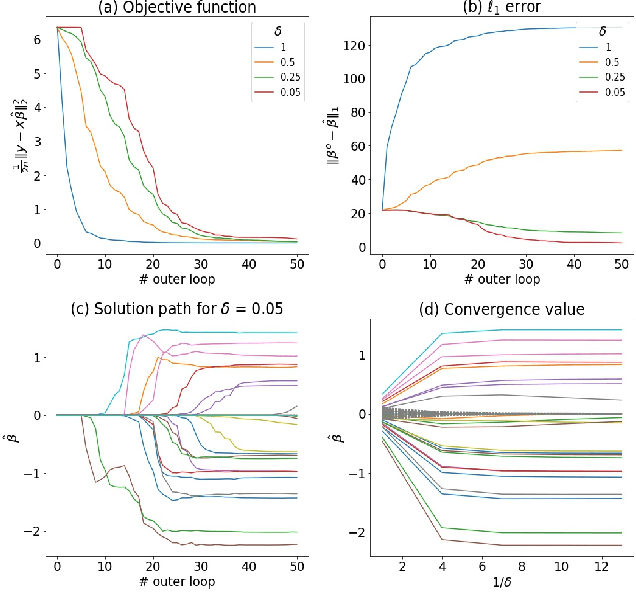
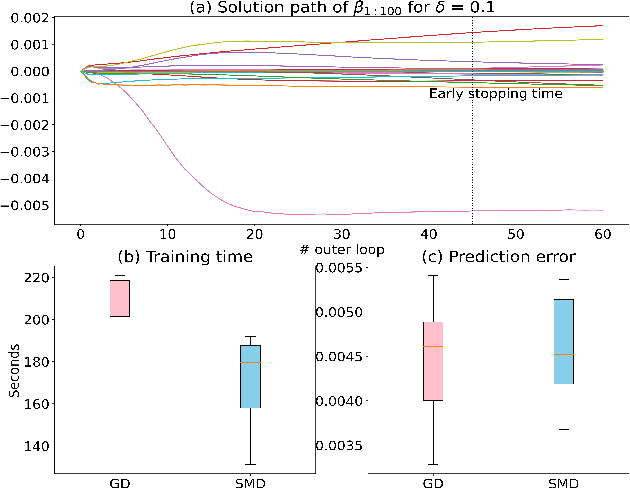
In machine learning and statistical data analysis, we often run into objective function that is a summation: the number of terms in the summation possibly is equal to the sample size, which can be enormous. In such a setting, the stochastic mirror descent (SMD) algorithm is a numerically efficient method -- each iteration involving a very small subset of the data. The variance reduction version of SMD (VRSMD) can further improve SMD by inducing faster convergence. On the other hand, algorithms such as gradient descent and stochastic gradient descent have the implicit regularization property that leads to better performance in terms of the generalization errors. Little is known on whether such a property holds for VRSMD. We prove here that the discrete VRSMD estimator sequence converges to the minimum mirror interpolant in the linear regression. This establishes the implicit regularization property for VRSMD. As an application of the above result, we derive a model estimation accuracy result in the setting when the true model is sparse. We use numerical examples to illustrate the empirical power of VRSMD.
An Accelerated Stochastic Algorithm for Solving the Optimal Transport Problem
Mar 22, 2022
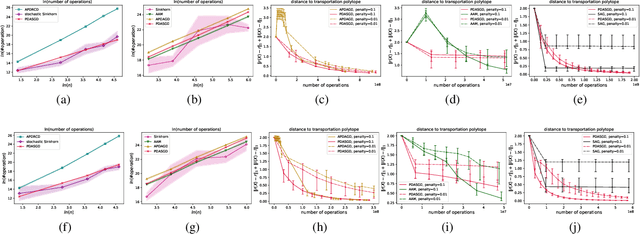
We propose a novel accelerated stochastic algorithm -- primal-dual accelerated stochastic gradient descent with variance reduction (PDASGD) -- for solving the optimal transport (OT) problem between two discrete distributions. PDASGD can also be utilized to compute for the Wasserstein barycenter (WB) of multiple discrete distributions. In both the OT and WB cases, the proposed algorithm enjoys the best-known convergence rate (in the form of order of computational complexity) in the literature. PDASGD is easy to implement in nature, due to its stochastic property: computation per iteration can be much faster than other non-stochastic counterparts. We carry out numerical experiments on both synthetic and real data; they demonstrate the improved efficiency of PDASGD.