 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence-Generated Terahertz Multi-Resonant Metasurfaces via Improved Transformer and CGAN Neural Networks
Jul 21, 2023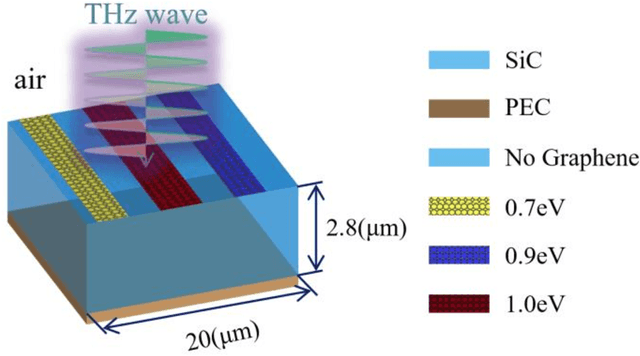
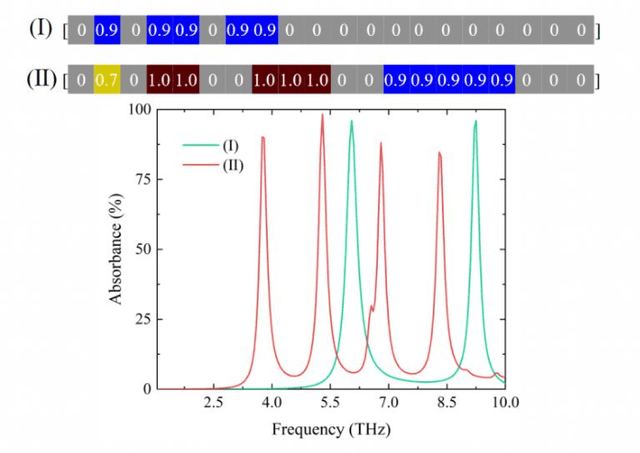
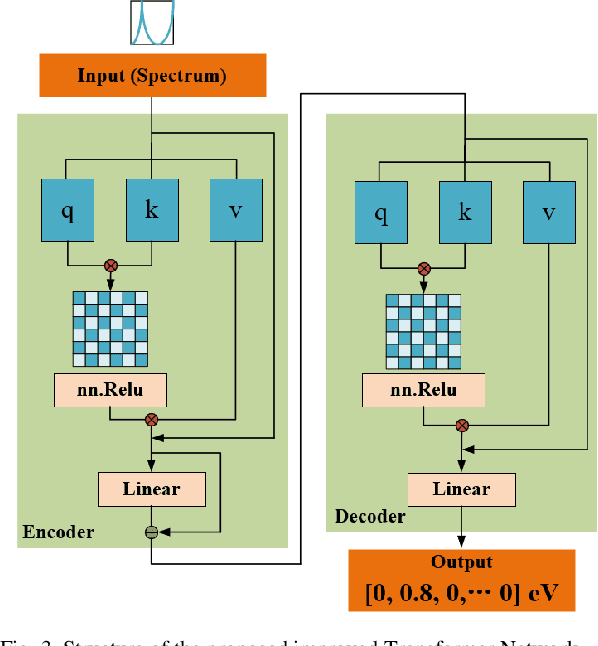
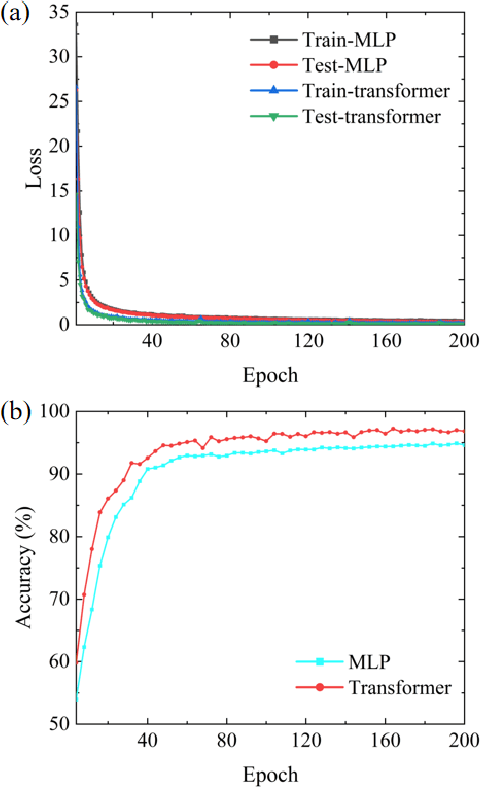
It is well known that the inverse design of terahertz (THz) multi-resonant graphene metasurfaces by using traditional deep neural networks (DNNs) has limited generalization ability. In this paper, we propose improved Transformer and conditional generative adversarial neural networks (CGAN) for the inverse design of graphene metasurfaces based upon THz multi-resonant absorption spectra. The improved Transformer can obtain higher accuracy and generalization performance in the StoV (Spectrum to Vector) design compared to traditional multilayer perceptron (MLP) neural networks, while the StoI (Spectrum to Image) design achieved through CGAN can provide more comprehensive information and higher accuracy than the StoV design obtained by MLP. Moreover, the improved CGAN can achieve the inverse design of graphene metasurface images directly from the desired multi-resonant absorption spectra. It is turned out that this work can finish facilitating the design process of artificial intelligence-generated metasurfaces (AIGM), and even provide a useful guide for developing complex THz metasurfaces based on 2D materials using generative neural networks.
Deep Dual Relation Modeling for Egocentric Interaction Recognition
May 31, 2019
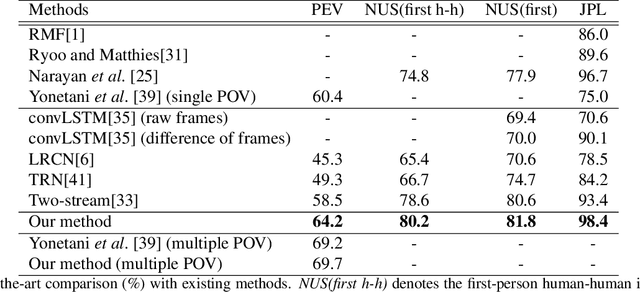
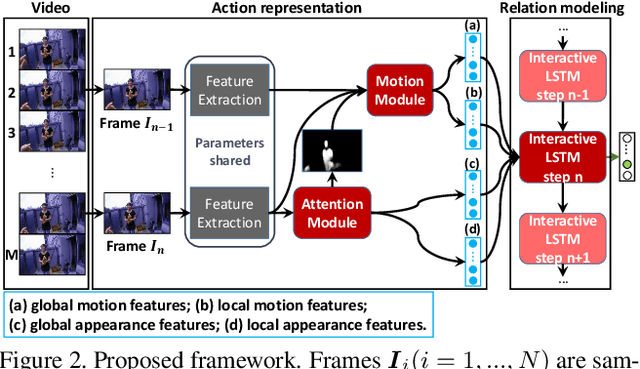
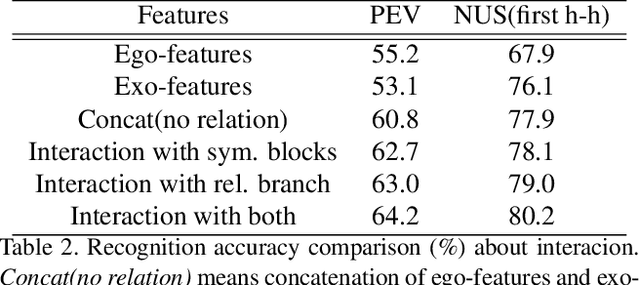
Egocentric interaction recognition aims to recognize the camera wearer's interactions with the interactor who faces the camera wearer in egocentric videos. In such a human-human interaction analysis problem, it is crucial to explore the relations between the camera wearer and the interactor. However, most existing works directly model the interactions as a whole and lack modeling the relations between the two interacting persons. To exploit the strong relations for egocentric interaction recognition, we introduce a dual relation modeling framework which learns to model the relations between the camera wearer and the interactor based on the individual action representations of the two persons. Specifically, we develop a novel interactive LSTM module, the key component of our framework, to explicitly model the relations between the two interacting persons based on their individual action representations, which are collaboratively learned with an interactor attention module and a global-local motion module. Experimental results on three egocentric interaction datasets show the effectiveness of our method and advantage over state-of-the-arts.