 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Single- and Multi-task Text Classification through Large Language Model Fine-tuning
Dec 11, 2024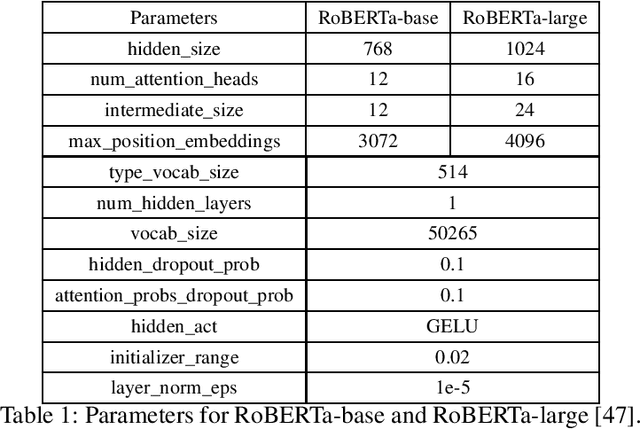
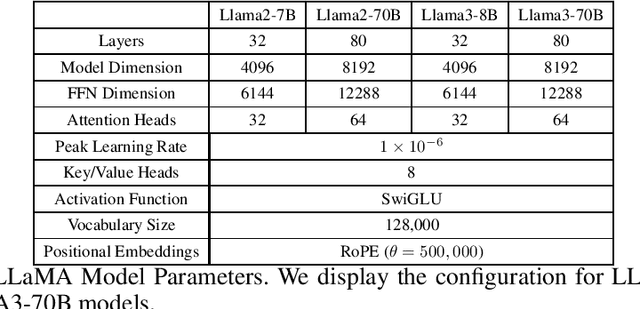
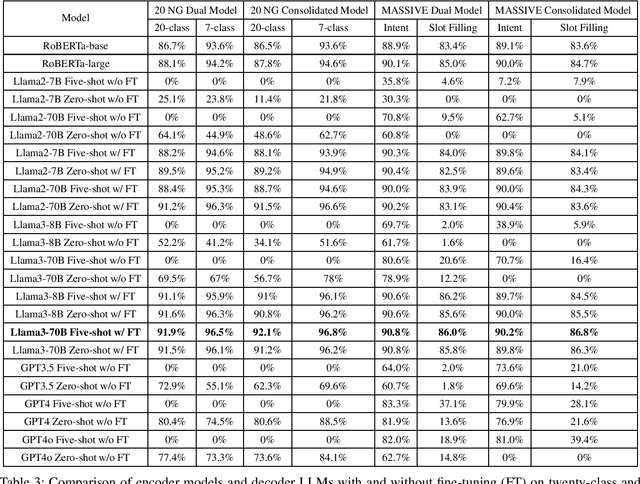
Both encoder-only models (e.g., BERT, RoBERTa) and large language models (LLMs, e.g., Llama3) have been widely used for text classification tasks. However, there is a lack of systematic studies comparing the performance of encoder-based models and LLMs in text classification, particularly when fine-tuning is involved. This study employed a diverse range of models and methods, varying in size and architecture, and including both fine-tuned and pre-trained approaches. We first assessed the performances of these LLMs on the 20 Newsgroups (20NG) and MASSIVE datasets, comparing them to encoder-only RoBERTa models. Additionally, we explored the multi-task capabilities of both model types by combining multiple classification tasks, including intent detection and slot-filling, into a single model using data from both datasets. Our results indicate that fully fine-tuned Llama3-70B models outperform RoBERTa-large and other decoder LLMs across various classification tasks and datasets. Moreover, the consolidated multi-task fine-tuned LLMs matched the performance of dual-model setups in both tasks across both datasets. Overall, our study provides a comprehensive benchmark of encoder-only and LLM models on text classification tasks and demonstrates a method to combine two or more fully fine-tuned decoder LLMs for reduced latency and equivalent performance.