 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISK: A Framework for GUI Agents in E-commerce Risk Management
Sep 26, 2025E-commerce risk management requires aggregating diverse, deeply embedded web data through multi-step, stateful interactions, which traditional scraping methods and most existing Graphical User Interface (GUI) agents cannot handle. These agents are typically limited to single-step tasks and lack the ability to manage dynamic, interactive content critical for effective risk assessment. To address this challenge, we introduce RISK, a novel framework designed to build and deploy GUI agents for this domain. RISK integrates three components: (1) RISK-Data, a dataset of 8,492 single-step and 2,386 multi-step interaction trajectories, collected through a high-fidelity browser framework and a meticulous data curation process; (2) RISK-Bench, a benchmark with 802 single-step and 320 multi-step trajectories across three difficulty levels for standardized evaluation; and (3) RISK-R1, a R1-style reinforcement fine-tuning framework considering four aspects: (i) Output Format: Updated format reward to enhance output syntactic correctness and task comprehension, (ii) Single-step Level: Stepwise accuracy reward to provide granular feedback during early training stages, (iii) Multi-step Level: Process reweight to emphasize critical later steps in interaction sequences, and (iv) Task Level: Level reweight to focus on tasks of varying difficulty. Experiments show that RISK-R1 outperforms existing baselines, achieving a 6.8% improvement in offline single-step and an 8.8% improvement in offline multi-step. Moreover, it attains a top task success rate of 70.5% in online evaluation. RISK provides a scalable, domain-specific solution for automating complex web interactions, advancing the state of the art in e-commerce risk management.
SSHNN: Semi-Supervised Hybrid NAS Network for Echocardiographic Image Segmentation
Sep 09, 2023


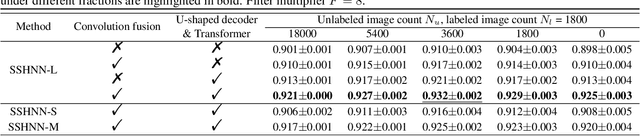
Accurate medical image segmentation especially for echocardiographic images with unmissable noise requires elaborate network design. Compared with manual design, Neural Architecture Search (NAS) realizes better segmentation results due to larger search space and automatic optimization, but most of the existing methods are weak in layer-wise feature aggregation and adopt a ``strong encoder, weak decoder" structure, insufficient to handle global relationships and local details. To resolve these issues, we propose a novel semi-supervised hybrid NAS network for accurate medical image segmentation termed SSHNN. In SSHNN, we creatively use convolution operation in layer-wise feature fusion instead of normalized scalars to avoid losing details, making NAS a stronger encoder. Moreover, Transformers are introduced for the compensation of global context and U-shaped decoder is designed to efficiently connect global context with local features. Specifically, we implement a semi-supervised algorithm Mean-Teacher to overcome the limited volume problem of labeled medical image dataset. Extensive experiments on CAMUS echocardiography dataset demonstrate that SSHNN outperforms state-of-the-art approaches and realizes accurate segmentation. Code will be made publicly available.
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 16, 2021
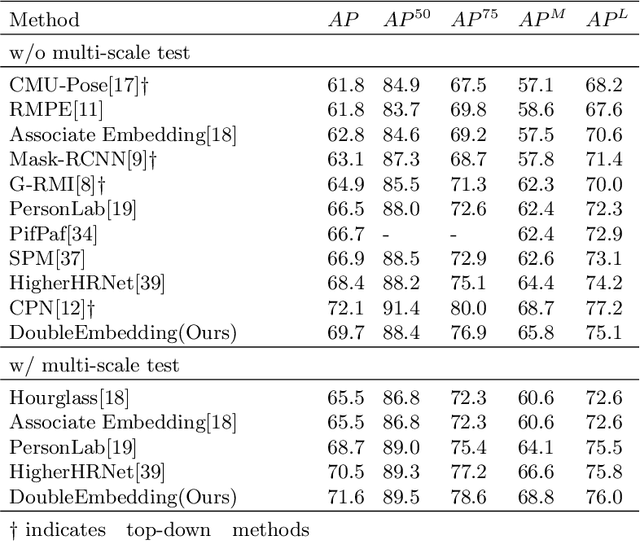
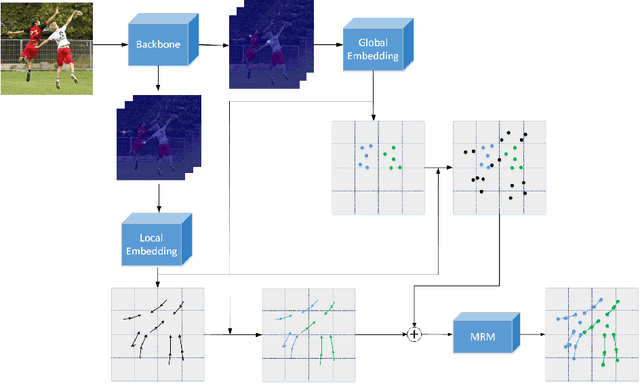
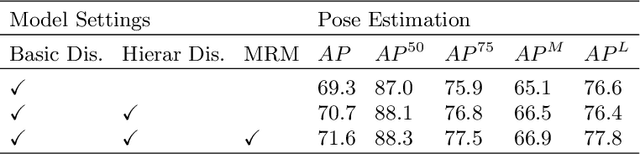
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.