 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Informativeness Gap of (Mis)Calibrated Predictors
Jul 16, 2025In many applications, decision-makers must choose between multiple predictive models that may all be miscalibrated. Which model (i.e., predictor) is more "useful" in downstream decision tasks? To answer this, our first contribution introduces the notion of the informativeness gap between any two predictors, defined as the maximum normalized payoff advantage one predictor offers over the other across all decision-making tasks. Our framework strictly generalizes several existing notions: it subsumes U-Calibration [KLST-23] and Calibration Decision Loss [HW-24], which compare a miscalibrated predictor to its calibrated counterpart, and it recovers Blackwell informativeness [Bla-51, Bla-53] as a special case when both predictors are perfectly calibrated. Our second contribution is a dual characterization of the informativeness gap, which gives rise to a natural informativeness measure that can be viewed as a relaxed variant of the earth mover's distance (EMD) between two prediction distributions. We show that this measure satisfies natural desiderata: it is complete and sound, and it can be estimated sample-efficiently in the prediction-only access setting. Along the way, we also obtain novel combinatorial structural results when applying this measure to perfectly calibrated predictors.
Persuasive Calibration
Apr 04, 2025

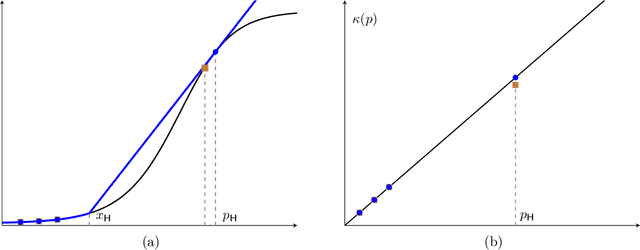

We introduce and study the persuasive calibration problem, where a principal aims to provide trustworthy predictions about underlying events to a downstream agent to make desired decisions. We adopt the standard calibration framework that regulates predictions to be unbiased conditional on their own value, and thus, they can reliably be interpreted at the face value by the agent. Allowing a small calibration error budget, we aim to answer the following question: what is and how to compute the optimal predictor under this calibration error budget, especially when there exists incentive misalignment between the principal and the agent? We focus on standard Lt-norm Expected Calibration Error (ECE) metric. We develop a general framework by viewing predictors as post-processed versions of perfectly calibrated predictors. Using this framework, we first characterize the structure of the optimal predictor. Specifically, when the principal's utility is event-independent and for L1-norm ECE, we show: (1) the optimal predictor is over-(resp. under-) confident for high (resp. low) true expected outcomes, while remaining perfectly calibrated in the middle; (2) the miscalibrated predictions exhibit a collinearity structure with the principal's utility function. On the algorithmic side, we provide a FPTAS for computing approximately optimal predictor for general principal utility and general Lt-norm ECE. Moreover, for the L1- and L-Infinity-norm ECE, we provide polynomial-time algorithms that compute the exact optimal predictor.
Dynamic Pricing and Learning with Bayesian Persuasion
Apr 27, 2023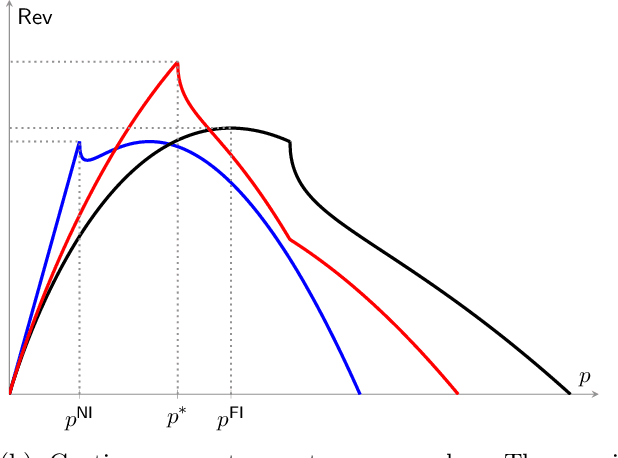


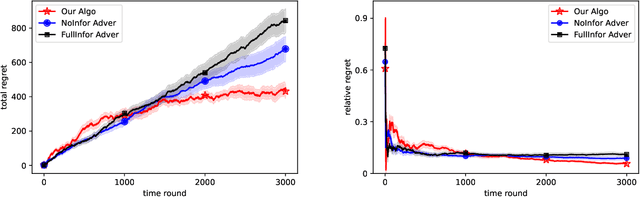
We consider a novel dynamic pricing and learning setting where in addition to setting prices of products in sequential rounds, the seller also ex-ante commits to 'advertising schemes'. That is, in the beginning of each round the seller can decide what kind of signal they will provide to the buyer about the product's quality upon realization. Using the popular Bayesian persuasion framework to model the effect of these signals on the buyers' valuation and purchase responses, we formulate the problem of finding an optimal design of the advertising scheme along with a pricing scheme that maximizes the seller's expected revenue. Without any apriori knowledge of the buyers' demand function, our goal is to design an online algorithm that can use past purchase responses to adaptively learn the optimal pricing and advertising strategy. We study the regret of the algorithm when compared to the optimal clairvoyant price and advertising scheme. Our main result is a computationally efficient online algorithm that achieves an $O(T^{2/3}(m\log T)^{1/3})$ regret bound when the valuation function is linear in the product quality. Here $m$ is the cardinality of the discrete product quality domain and $T$ is the time horizon. This result requires some natural monotonicity and Lipschitz assumptions on the valuation function, but no Lipschitz or smoothness assumption on the buyers' demand function. For constant $m$, our result matches the regret lower bound for dynamic pricing within logarithmic factors, which is a special case of our problem. We also obtain several improved results for the widely considered special case of additive valuations, including an $\tilde{O}(T^{2/3})$ regret bound independent of $m$ when $m\le T^{1/3}$.
Online Bayesian Recommendation with No Regret
Feb 12, 2022We introduce and study the online Bayesian recommendation problem for a platform, who can observe a utility-relevant state of a product, repeatedly interacting with a population of myopic users through an online recommendation mechanism. This paradigm is common in a wide range of scenarios in the current Internet economy. For each user with her own private preference and belief, the platform commits to a recommendation strategy to utilize his information advantage on the product state to persuade the self-interested user to follow the recommendation. The platform does not know user's preferences and beliefs, and has to use an adaptive recommendation strategy to persuade with gradually learning user's preferences and beliefs in the process. We aim to design online learning policies with no Stackelberg regret for the platform, i.e., against the optimum policy in hindsight under the assumption that users will correspondingly adapt their behaviors to the benchmark policy. Our first result is an online policy that achieves double logarithm regret dependence on the number of rounds. We then present a hardness result showing that no adaptive online policy can achieve regret with better dependency on the number of rounds. Finally, by formulating the platform's problem as optimizing a linear program with membership oracle access, we present our second online policy that achieves regret with polynomial dependence on the number of states but logarithm dependence on the number of rounds.