 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotionX-IDEA: Emotion BERT -- an Affectional Model for Conversation
Aug 17, 2019
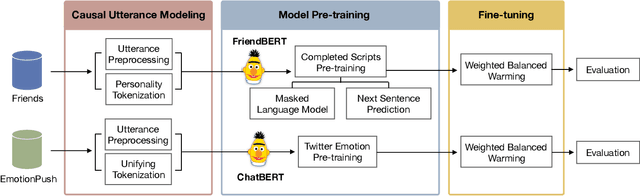


In this paper, we investigate the emotion recognition ability of the pre-training language model, namely BERT. By the nature of the framework of BERT, a two-sentence structure, we adapt BERT to continues dialogue emotion prediction tasks, which rely heavily on the sentence-level context-aware understanding. The experiments show that by mapping the continues dialogue into a causal utterance pair, which is constructed by the utterance and the reply utterance, models can better capture the emotions of the reply utterance. The present method has achieved 0.815 and 0.885 micro F1 score in the testing dataset of Friends and EmotionPush, respectively.
Leveraging Linguistic Characteristics for Bipolar Disorder Recognition with Gender Differences
Jul 17, 2019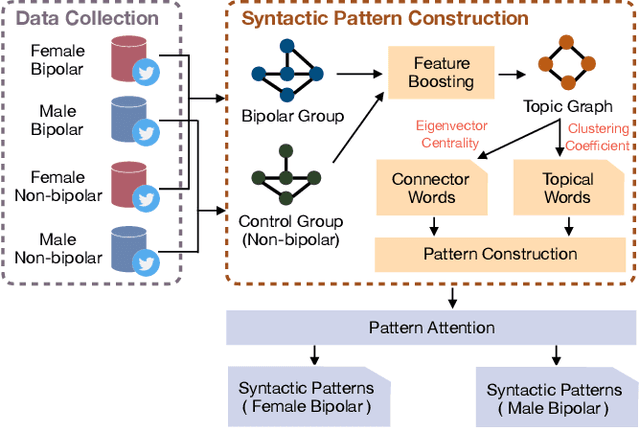
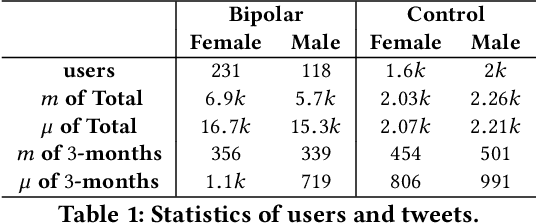
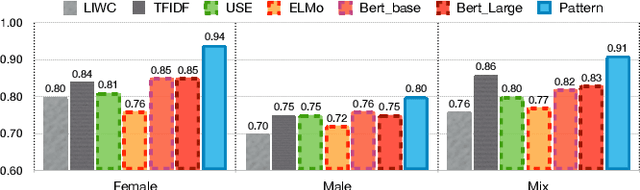

Most previous studies on automatic recognition model for bipolar disorder (BD) were based on both social media and linguistic features. The present study investigates the possibility of adopting only language-based features, namely the syntax and morpheme collocation. We also examine the effect of gender on the results considering gender has long been recognized as an important modulating factor for mental disorders, yet it received little attention in previous linguistic models. The present study collects Twitter posts 3 months prior to the self-disclosure by 349 BD users (231 female, 118 male). We construct a set of syntactic patterns in terms of the word usage based on graph pattern construction and pattern attention mechanism. The factors examined are gender differences, syntactic patterns, and bipolar recognition performance. The performance indicates our F1 scores reach over 91% and outperform several baselines, including those using TF-IDF, LIWC and pre-trained language models (ELMO and BERT). The contributions of the present study are: (1) The features are contextualized, domain-agnostic, and purely linguistic. (2) The performance of BD recognition is improved by gender-enriched linguistic pattern features, which are constructed with gender differences in language usage.
Facebook Reaction-Based Emotion Classifier as Cue for Sarcasm Detection
May 04, 2018

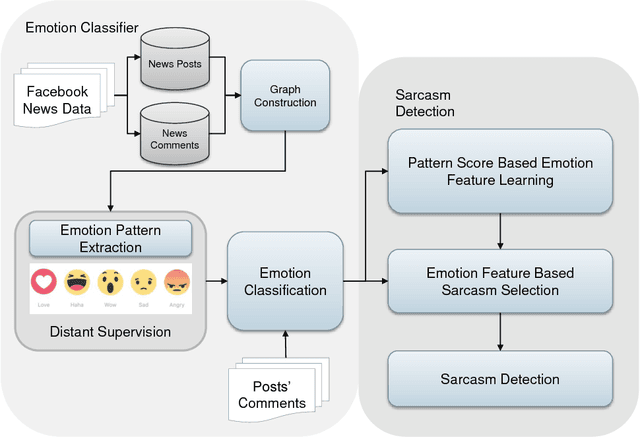
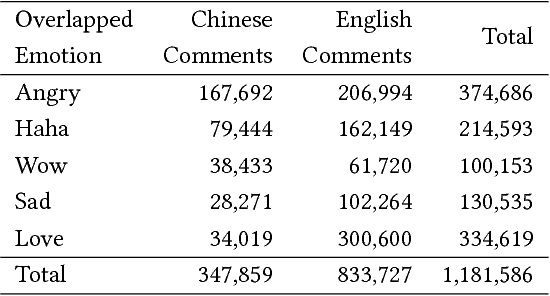
Online social media users react to content in them based on context. Emotions or mood play a significant part of these reactions, which has filled these platforms with opinionated content. Different approaches and applications to make better use of this data are continuously being developed. However, due to the nature of the data, the variety of platforms, and dynamic online user behavior, there are still many issues to be dealt with. It remains a challenge to properly obtain a reliable emotional status from a user prior to posting a comment. This work introduces a methodology that explores semi-supervised multilingual emotion detection based on the overlap of Facebook reactions and textual data. With the resulting emotion detection system we evaluate the possibility of using emotions and user behavior features for the task of sarcasm detection. More than 1 million English and Chinese comments from over 62,000 public Facebook pages posts have been collected and processed, conducted experiments show acceptable performance metrics.
DeepEmo: Learning and Enriching Pattern-Based Emotion Representations
Apr 24, 2018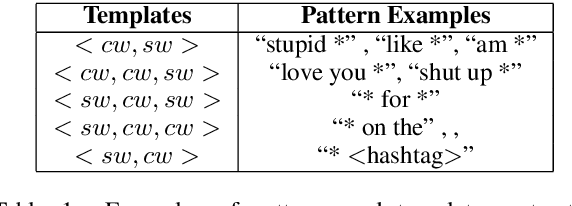
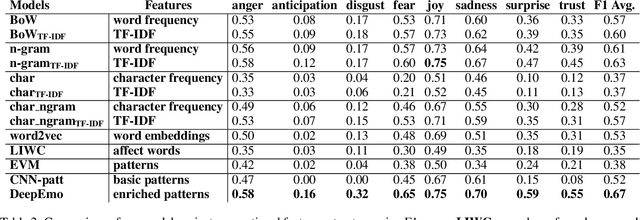

We propose a graph-based mechanism to extract rich-emotion bearing patterns, which fosters a deeper analysis of online emotional expressions, from a corpus. The patterns are then enriched with word embeddings and evaluated through several emotion recognition tasks. Moreover, we conduct analysis on the emotion-oriented patterns to demonstrate its applicability and to explore its properties. Our experimental results demonstrate that the proposed techniques outperform most state-of-the-art emotion recognition techniques.
Surfacing contextual hate speech words within social media
Nov 28, 2017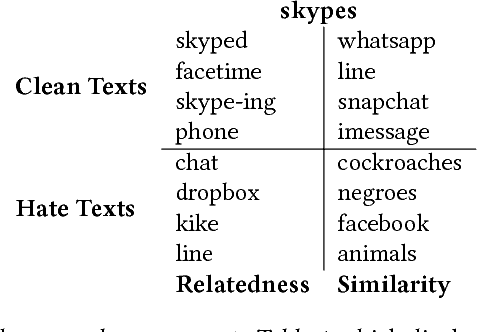
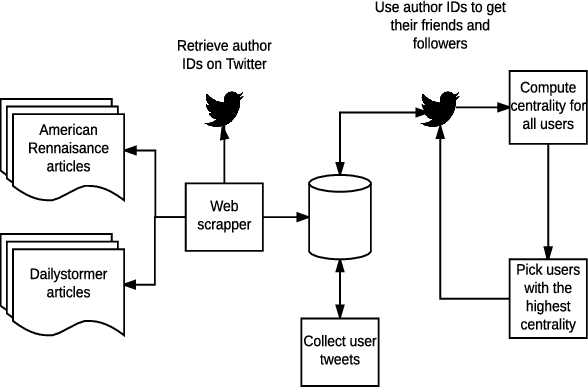
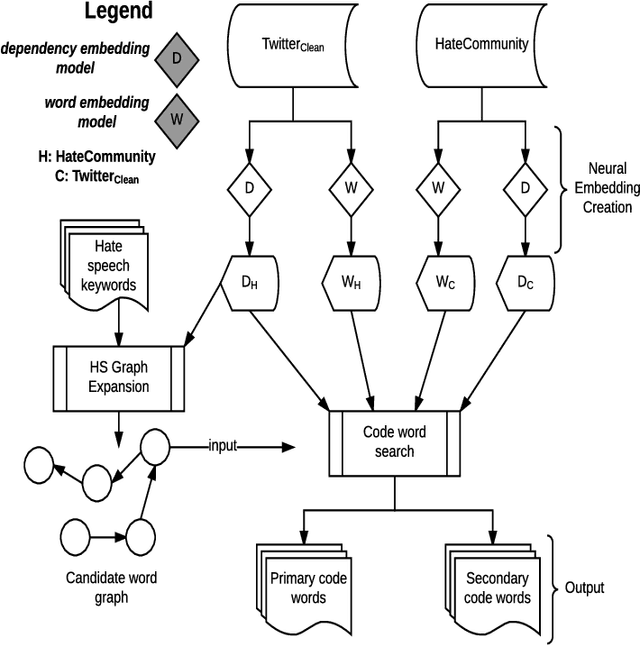
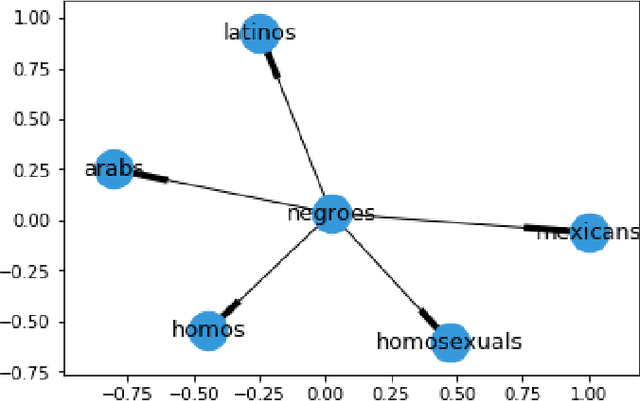
Social media platforms have recently seen an increase in the occurrence of hate speech discourse which has led to calls for improved detection methods. Most of these rely on annotated data, keywords, and a classification technique. While this approach provides good coverage, it can fall short when dealing with new terms produced by online extremist communities which act as original sources of words which have alternate hate speech meanings. These code words (which can be both created and adopted words) are designed to evade automatic detection and often have benign meanings in regular discourse. As an example, "skypes", "googles", and "yahoos" are all instances of words which have an alternate meaning that can be used for hate speech. This overlap introduces additional challenges when relying on keywords for both the collection of data that is specific to hate speech, and downstream classification. In this work, we develop a community detection approach for finding extremist hate speech communities and collecting data from their members. We also develop a word embedding model that learns the alternate hate speech meaning of words and demonstrate the candidacy of our code words with several annotation experiments, designed to determine if it is possible to recognize a word as being used for hate speech without knowing its alternate meaning. We report an inter-annotator agreement rate of K=0.871, and K=0.676 for data drawn from our extremist community and the keyword approach respectively, supporting our claim that hate speech detection is a contextual task and does not depend on a fixed list of keywords. Our goal is to advance the domain by providing a high quality hate speech dataset in addition to learned code words that can be fed into existing classification approaches, thus improving the accuracy of automated detection.