 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I'm" Lost in Translation: Pronoun Missteps in Crowdsourced Data Sets
Apr 22, 2023


As virtual assistants continue to be taken up globally, there is an ever-greater need for these speech-based systems to communicate naturally in a variety of languages. Crowdsourcing initiatives have focused on multilingual translation of big, open data sets for use in natural language processing (NLP). Yet, language translation is often not one-to-one, and biases can trickle in. In this late-breaking work, we focus on the case of pronouns translated between English and Japanese in the crowdsourced Tatoeba database. We found that masculine pronoun biases were present overall, even though plurality in language was accounted for in other ways. Importantly, we detected biases in the translation process that reflect nuanced reactions to the presence of feminine, neutral, and/or non-binary pronouns. We raise the issue of translation bias for pronouns and offer a practical solution to embed plurality in NLP data sets.
* 6 pages
Trust and Reliance in Consensus-Based Explanations from an Anti-Misinformation Agent
Apr 22, 2023The illusion of consensus occurs when people believe there is consensus across multiple sources, but the sources are the same and thus there is no "true" consensus. We explore this phenomenon in the context of an AI-based intelligent agent designed to augment metacognition on social media. Misinformation, especially on platforms like Twitter, is a global problem for which there is currently no good solution. As an explainable AI (XAI) system, the agent provides explanations for its decisions on the misinformed nature of social media content. In this late-breaking study, we explored the roles of trust (attitude) and reliance (behaviour) as key elements of XAI user experience (UX) and whether these influenced the illusion of consensus. Findings show no effect of trust, but an effect of reliance on consensus-based explanations. This work may guide the design of anti-misinformation systems that use XAI, especially the user-centred design of explanations.
* 7 pages
Exoskeleton for the Mind: Exploring Strategies Against Misinformation with a Metacognitive Agent
Apr 18, 2023Misinformation is a global problem in modern social media platforms with few solutions known to be effective. Social media platforms have offered tools to raise awareness of information, but these are closed systems that have not been empirically evaluated. Others have developed novel tools and strategies, but most have been studied out of context using static stimuli, researcher prompts, or low fidelity prototypes. We offer a new anti-misinformation agent grounded in theories of metacognition that was evaluated within Twitter. We report on a pilot study (n=17) and multi-part experimental study (n=57, n=49) where participants experienced three versions of the agent, each deploying a different strategy. We found that no single strategy was superior over the control. We also confirmed the necessity of transparency and clarity about the agent's underlying logic, as well as concerns about repeated exposure to misinformation and lack of user engagement.
* Pages 209-220
Trust in Human-AI Interaction: Scoping Out Models, Measures, and Methods
Apr 30, 2022
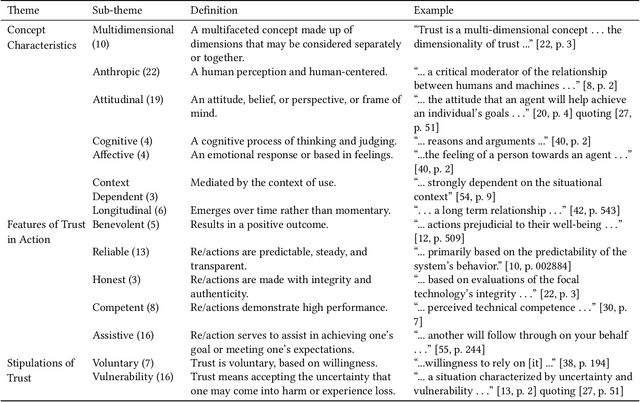
Trust has emerged as a key factor in people's interactions with AI-infused systems. Yet, little is known about what models of trust have been used and for what systems: robots, virtual characters, smart vehicles, decision aids, or others. Moreover, there is yet no known standard approach to measuring trust in AI. This scoping review maps out the state of affairs on trust in human-AI interaction (HAII) from the perspectives of models, measures, and methods. Findings suggest that trust is an important and multi-faceted topic of study within HAII contexts. However, most work is under-theorized and under-reported, generally not using established trust models and missing details about methods, especially Wizard of Oz. We offer several targets for systematic review work as well as a research agenda for combining the strengths and addressing the weaknesses of the current literature.
* Accepted at CHI EA '22