 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAPRAD: LLM-Assisted PRotocol Attack Discovery
Oct 22, 2025


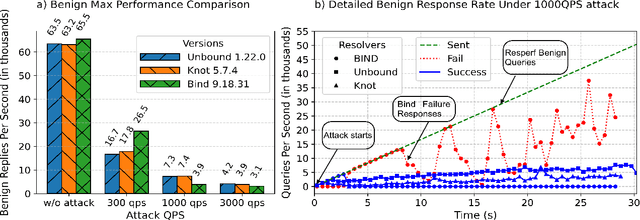
With the goal of improving the security of Internet protocols, we seek faster, semi-automatic methods to discover new vulnerabilities in protocols such as DNS, BGP, and others. To this end, we introduce the LLM-Assisted Protocol Attack Discovery (LAPRAD) methodology, enabling security researchers with some DNS knowledge to efficiently uncover vulnerabilities that would otherwise be hard to detect. LAPRAD follows a three-stage process. In the first, we consult an LLM (GPT-o1) that has been trained on a broad corpus of DNS-related sources and previous DDoS attacks to identify potential exploits. In the second stage, a different LLM automatically constructs the corresponding attack configurations using the ReACT approach implemented via LangChain (DNS zone file generation). Finally, in the third stage, we validate the attack's functionality and effectiveness. Using LAPRAD, we uncovered three new DDoS attacks on the DNS protocol and rediscovered two recently reported ones that were not included in the LLM's training data. The first new attack employs a bait-and-switch technique to trick resolvers into caching large, bogus DNSSEC RRSIGs, reducing their serving capacity to as little as 6%. The second exploits large DNSSEC encryption algorithms (RSA-4096) with multiple keys, thereby bypassing a recently implemented default RRSet limit. The third leverages ANY-type responses to produce a similar effect. These variations of a cache-flushing DDoS attack, called SigCacheFlush, circumvent existing patches, severely degrade resolver query capacity, and impact the latest versions of major DNS resolver implementations.
* IFIP Networking 2025 Proceedings (Accepted on 05.05.2025)
Holdout SGD: Byzantine Tolerant Federated Learning
Aug 11, 2020
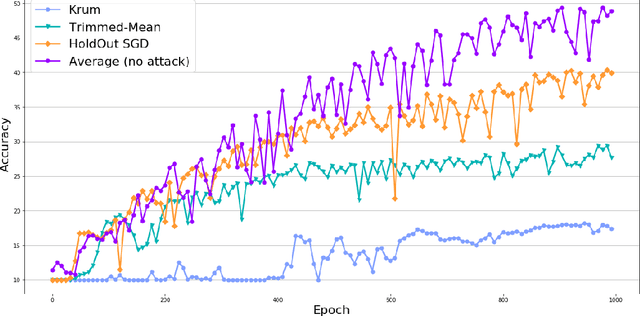
This work presents a new distributed Byzantine tolerant federated learning algorithm, HoldOut SGD, for Stochastic Gradient Descent (SGD) optimization. HoldOut SGD uses the well known machine learning technique of holdout estimation, in a distributed fashion, in order to select parameter updates that are likely to lead to models with low loss values. This makes it more effective at discarding Byzantine workers inputs than existing methods that eliminate outliers in the parameter-space of the learned model. HoldOut SGD first randomly selects a set of workers that use their private data in order to propose gradient updates. Next, a voting committee of workers is randomly selected, and each voter uses its private data as holdout data, in order to select the best proposals via a voting scheme. We propose two possible mechanisms for the coordination of workers in the distributed computation of HoldOut SGD. The first uses a truthful central server and corresponds to the typical setting of current federated learning. The second is fully distributed and requires no central server, paving the way to fully decentralized federated learning. The fully distributed version implements HoldOut SGD via ideas from the blockchain domain, and specifically the Algorand committee selection and consensus processes. We provide formal guarantees for the HoldOut SGD process in terms of its convergence to the optimal model, and its level of resilience to the fraction of Byzantine workers. Empirical evaluation shows that HoldOut SGD is Byzantine-resilient and efficiently converges to an effectual model for deep-learning tasks, as long as the total number of participating workers is large and the fraction of Byzantine workers is less than half (<1/3 for the fully distributed variant).