 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT Assisting Diagnosis of Neuro-ophthalmology Diseases Based on Case Reports
Sep 05, 2023Objective: To evaluate the efficiency of large language models (LLMs) such as ChatGPT to assist in diagnosing neuro-ophthalmic diseases based on detailed case descriptions. Methods: We selected 22 different case reports of neuro-ophthalmic diseases from a publicly available online database. These cases included a wide range of chronic and acute diseases that are commonly seen by neuro-ophthalmic sub-specialists. We inserted the text from each case as a new prompt into both ChatGPT v3.5 and ChatGPT Plus v4.0 and asked for the most probable diagnosis. We then presented the exact information to two neuro-ophthalmologists and recorded their diagnoses followed by comparison to responses from both versions of ChatGPT. Results: ChatGPT v3.5, ChatGPT Plus v4.0, and the two neuro-ophthalmologists were correct in 13 (59%), 18 (82%), 19 (86%), and 19 (86%) out of 22 cases, respectively. The agreement between the various diagnostic sources were as follows: ChatGPT v3.5 and ChatGPT Plus v4.0, 13 (59%); ChatGPT v3.5 and the first neuro-ophthalmologist, 12 (55%); ChatGPT v3.5 and the second neuro-ophthalmologist, 12 (55%); ChatGPT Plus v4.0 and the first neuro-ophthalmologist, 17 (77%); ChatGPT Plus v4.0 and the second neuro-ophthalmologist, 16 (73%); and first and second neuro-ophthalmologists 17 (17%). Conclusions: The accuracy of ChatGPT v3.5 and ChatGPT Plus v4.0 in diagnosing patients with neuro-ophthalmic diseases was 59% and 82%, respectively. With further development, ChatGPT Plus v4.0 may have potential to be used in clinical care settings to assist clinicians in providing quick, accurate diagnoses of patients in neuro-ophthalmology. The applicability of using LLMs like ChatGPT in clinical settings that lack access to subspeciality trained neuro-ophthalmologists deserves further research.
Using Large Language Models to Automate Category and Trend Analysis of Scientific Articles: An Application in Ophthalmology
Aug 31, 2023Purpose: In this paper, we present an automated method for article classification, leveraging the power of Large Language Models (LLM). The primary focus is on the field of ophthalmology, but the model is extendable to other fields. Methods: We have developed a model based on Natural Language Processing (NLP) techniques, including advanced LLMs, to process and analyze the textual content of scientific papers. Specifically, we have employed zero-shot learning (ZSL) LLM models and compared against Bidirectional and Auto-Regressive Transformers (BART) and its variants, and Bidirectional Encoder Representations from Transformers (BERT), and its variant such as distilBERT, SciBERT, PubmedBERT, BioBERT. Results: The classification results demonstrate the effectiveness of LLMs in categorizing large number of ophthalmology papers without human intervention. Results: To evalute the LLMs, we compiled a dataset (RenD) of 1000 ocular disease-related articles, which were expertly annotated by a panel of six specialists into 15 distinct categories. The model achieved mean accuracy of 0.86 and mean F1 of 0.85 based on the RenD dataset. Conclusion: The proposed framework achieves notable improvements in both accuracy and efficiency. Its application in the domain of ophthalmology showcases its potential for knowledge organization and retrieval in other domains too. We performed trend analysis that enables the researchers and clinicians to easily categorize and retrieve relevant papers, saving time and effort in literature review and information gathering as well as identification of emerging scientific trends within different disciplines. Moreover, the extendibility of the model to other scientific fields broadens its impact in facilitating research and trend analysis across diverse disciplines.
Stacking Ensemble Learning in Deep Domain Adaptation for Ophthalmic Image Classification
Sep 27, 2022Domain adaptation is an attractive approach given the availability of a large amount of labeled data with similar properties but different domains. It is effective in image classification tasks where obtaining sufficient label data is challenging. We propose a novel method, named SELDA, for stacking ensemble learning via extending three domain adaptation methods for effectively solving real-world problems. The major assumption is that when base domain adaptation models are combined, we can obtain a more accurate and robust model by exploiting the ability of each of the base models. We extend Maximum Mean Discrepancy (MMD), Low-rank coding, and Correlation Alignment (CORAL) to compute the adaptation loss in three base models. Also, we utilize a two-fully connected layer network as a meta-model to stack the output predictions of these three well-performing domain adaptation models to obtain high accuracy in ophthalmic image classification tasks. The experimental results using Age-Related Eye Disease Study (AREDS) benchmark ophthalmic dataset demonstrate the effectiveness of the proposed model.
Artificial Intelligence Models for Cell Type and Subtype Identification Based on Single-Cell RNA Sequencing Data in Vision Science
Sep 26, 2022
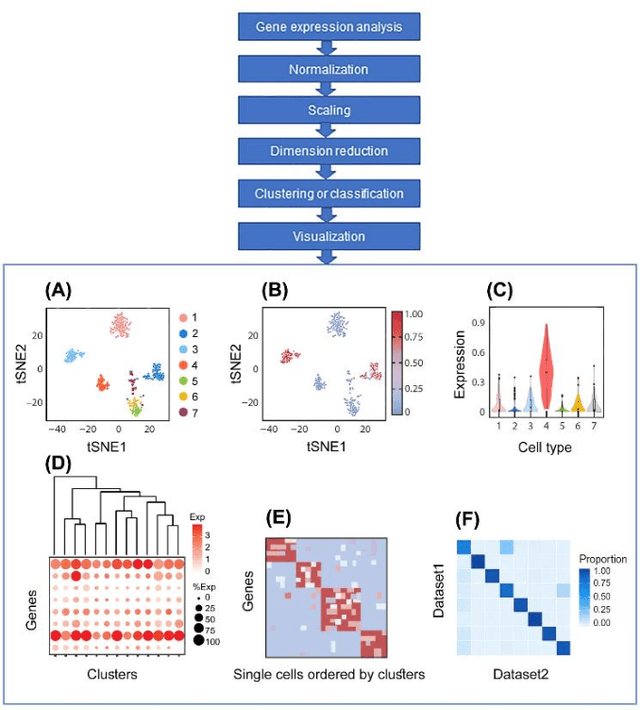

Single-cell RNA sequencing (scRNA-seq) provides a high throughput, quantitative and unbiased framework for scientists in many research fields to identify and characterize cell types within heterogeneous cell populations from various tissues. However, scRNA-seq based identification of discrete cell-types is still labor intensive and depends on prior molecular knowledge. Artificial intelligence has provided faster, more accurate, and user-friendly approaches for cell-type identification. In this review, we discuss recent advances in cell-type identification methods using artificial intelligence techniques based on single-cell and single-nucleus RNA sequencing data in vision science.