 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Malware Representation based on Execution Sequences
Dec 16, 2019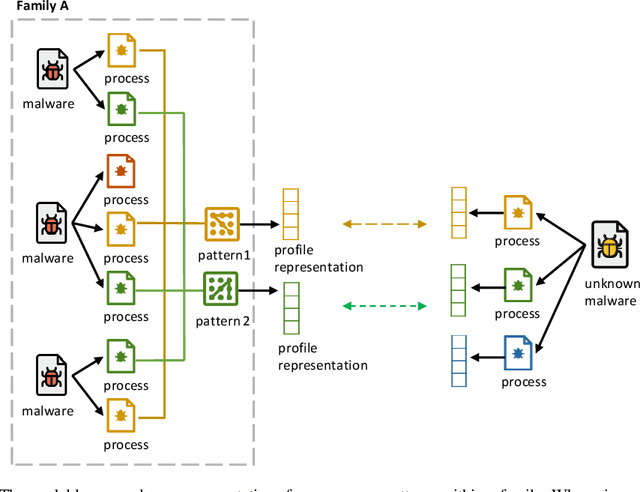
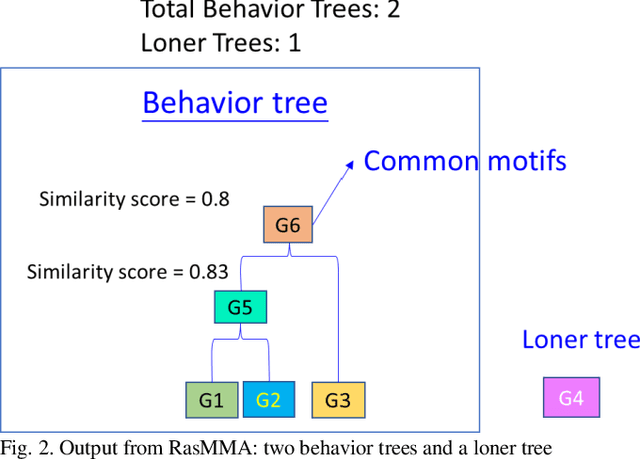
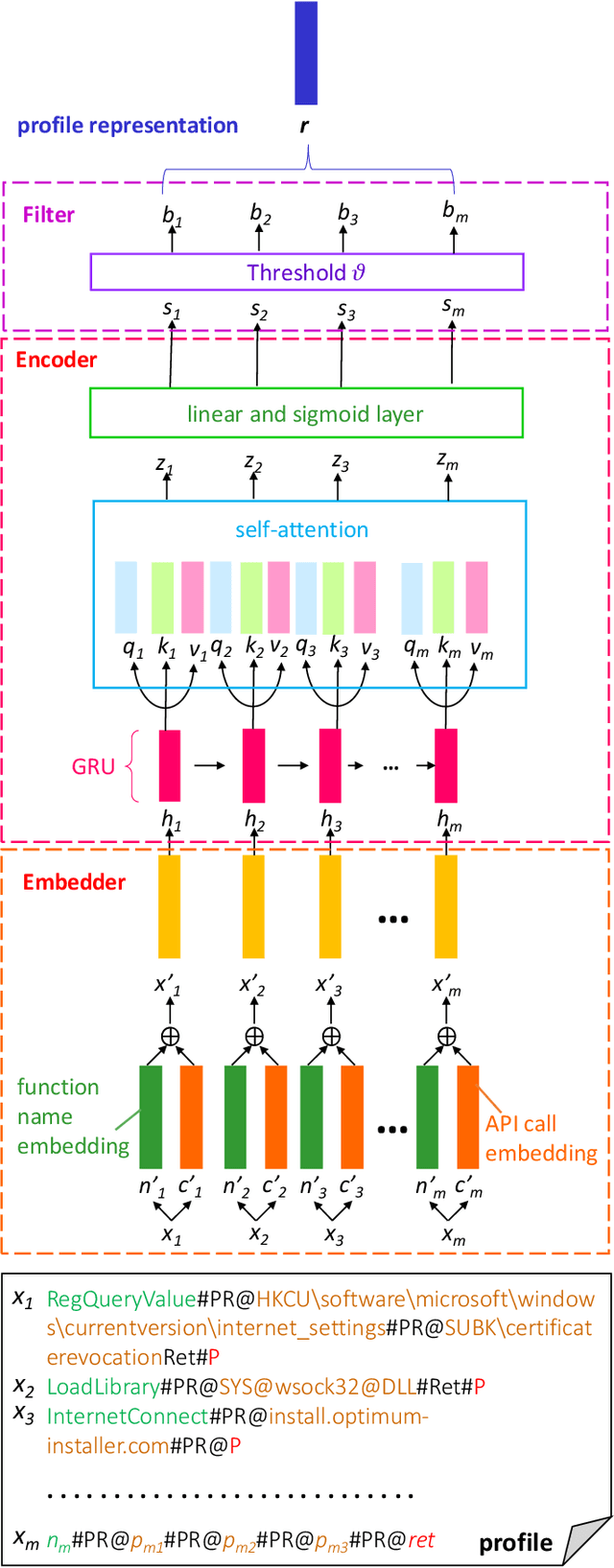
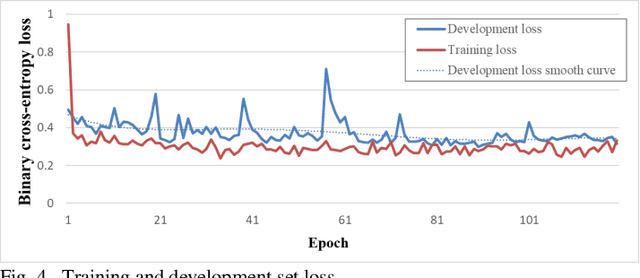
Malware analysis has been extensively investigated as the number and types of malware has increased dramatically. However, most previous studies use end-to-end systems to detect whether a sample is malicious, or to identify its malware family. In this paper, we propose a neural network framework composed of an embedder, an encoder, and a filter to learn malware representations from characteristic execution sequences for malware family classification. The embedder uses BERT and Sent2Vec, state-of-the-art embedding modules, to capture relations within a single API call and among consecutive API calls in an execution trace. The encoder comprises gated recurrent units (GRU) to preserve the ordinal position of API calls and a self-attention mechanism for comparing intra-relations among different positions of API calls. The filter identifies representative API calls to build the malware representation. We conduct broad experiments to determine the influence of individual framework components. The results show that the proposed framework outperforms the baselines, and also demonstrates that considering Sent2Vec to learn complete API call embeddings and GRU to explicitly preserve ordinal information yields more information and thus significant improvements. Also, the proposed approach effectively classifies new malicious execution traces on the basis of similarities with previously collected families.
Bringing personalized learning into computer-aided question generation
Aug 29, 2018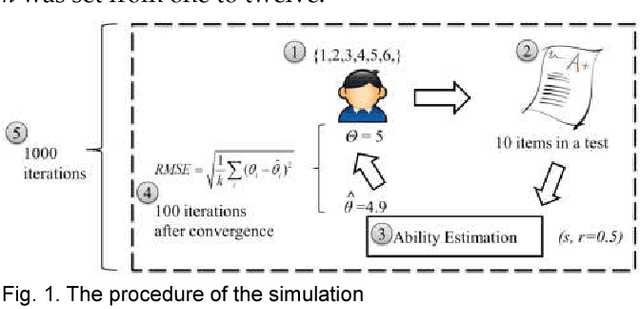
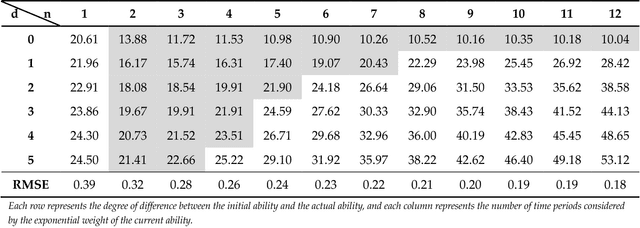
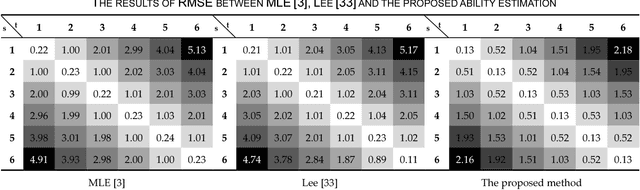
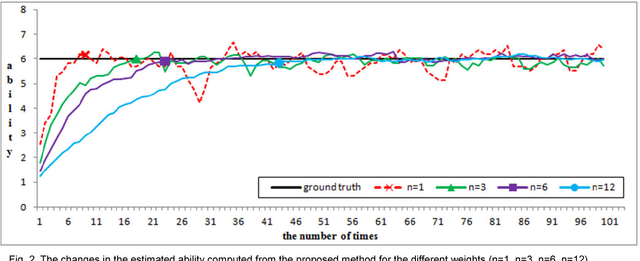
This paper proposes a novel and statistical method of ability estimation based on acquisition distribution for a personalized computer aided question generation. This method captures the learning outcomes over time and provides a flexible measurement based on the acquisition distributions instead of precalibration. Compared to the previous studies, the proposed method is robust, especially when an ability of a student is unknown. The results from the empirical data show that the estimated abilities match the actual abilities of learners, and the pretest and post-test of the experimental group show significant improvement. These results suggest that this method can serves as the ability estimation for a personalized computer-aided testing environment.
Development and Evaluation of a Personalized Computer-aided Question Generation for English Learners to Improve Proficiency and Correct Mistakes
Aug 29, 2018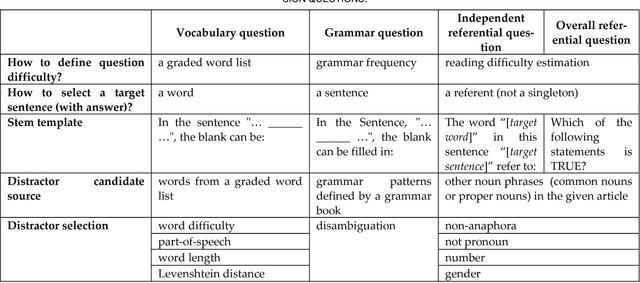
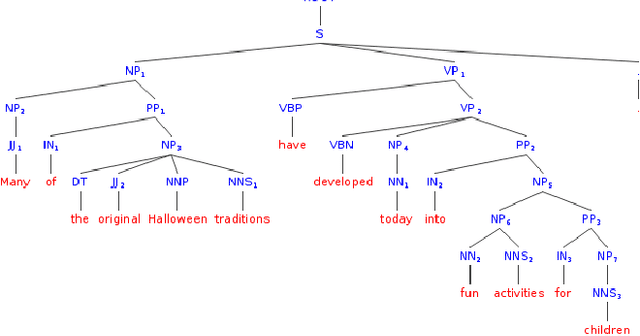
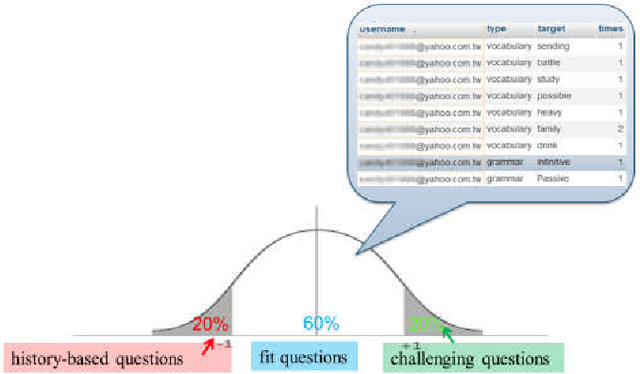
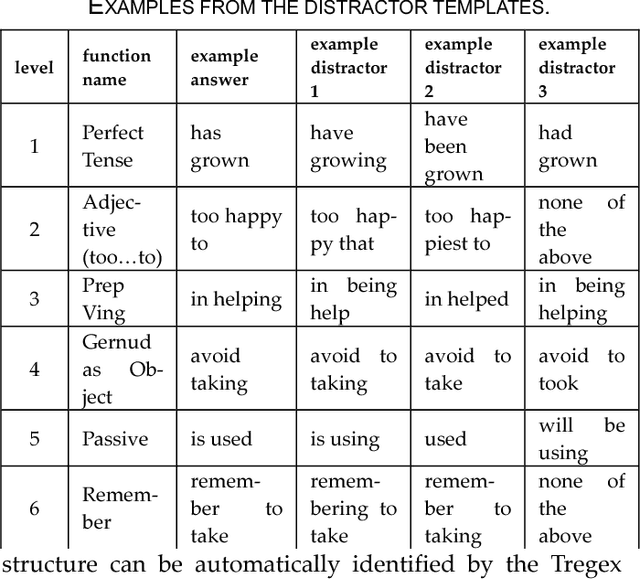
In the last several years, the field of computer assisted language learning has increasingly focused on computer aided question generation. However, this approach often provides test takers with an exhaustive amount of questions that are not designed for any specific testing purpose. In this work, we present a personalized computer aided question generation that generates multiple choice questions at various difficulty levels and types, including vocabulary, grammar and reading comprehension. In order to improve the weaknesses of test takers, it selects questions depending on an estimated proficiency level and unclear concepts behind incorrect responses. This results show that the students with the personalized automatic quiz generation corrected their mistakes more frequently than ones only with computer aided question generation. Moreover, students demonstrated the most progress between the pretest and post test and correctly answered more difficult questions. Finally, we investigated the personalizing strategy and found that a student could make a significant progress if the proposed system offered the vocabulary questions at the same level of his or her proficiency level, and if the grammar and reading comprehension questions were at a level lower than his or her proficiency level.
Characterizing the Influence of Features on Reading Difficulty Estimation for Non-native Readers
Aug 29, 2018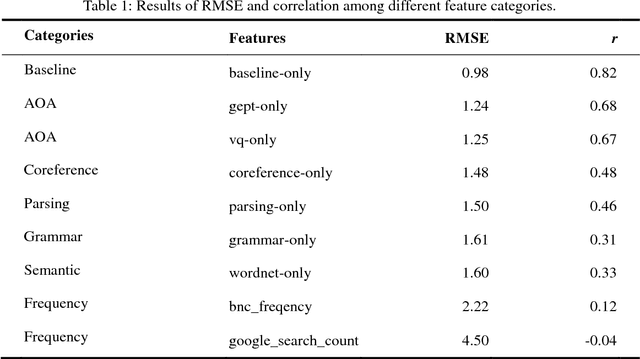
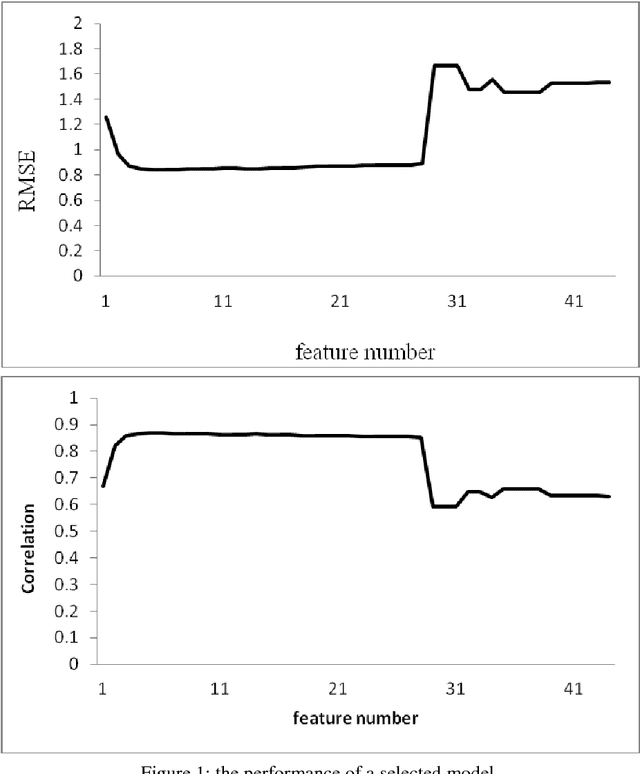

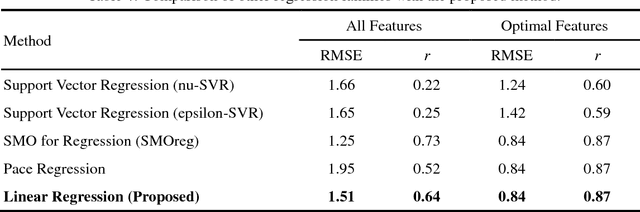
In recent years, the number of people studying English as a second language (ESL) has surpassed the number of native speakers. Recent work have demonstrated the success of providing personalized content based on reading difficulty, such as information retrieval and summarization. However, almost all prior studies of reading difficulty are designed for native speakers, rather than non-native readers. In this study, we investigate various features for ESL readers, by conducting a linear regression to estimate the reading level of English language sources. This estimation is based not only on the complexity of lexical and syntactic features, but also several novel concepts, including the age of word and grammar acquisition from several sources, word sense from WordNet, and the implicit relation between sentences. By employing Bayesian Information Criterion (BIC) to select the optimal model, we find that the combination of the number of words, the age of word acquisition and the height of the parsing tree generate better results than alternative competing models. Thus, our results show that proposed second language reading difficulty estimation outperforms other first language reading difficulty estimations.