 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Influence of Features on Reading Difficulty Estimation for Non-native Readers
Paper and Code
Aug 29, 2018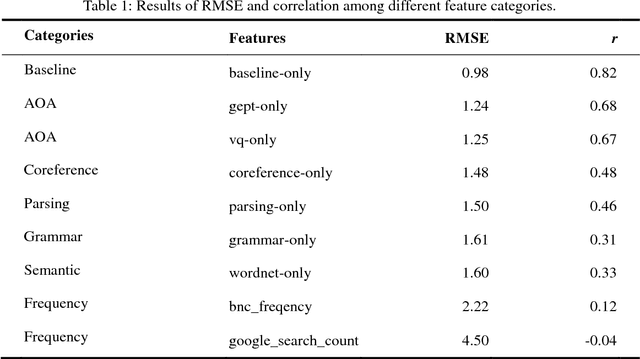
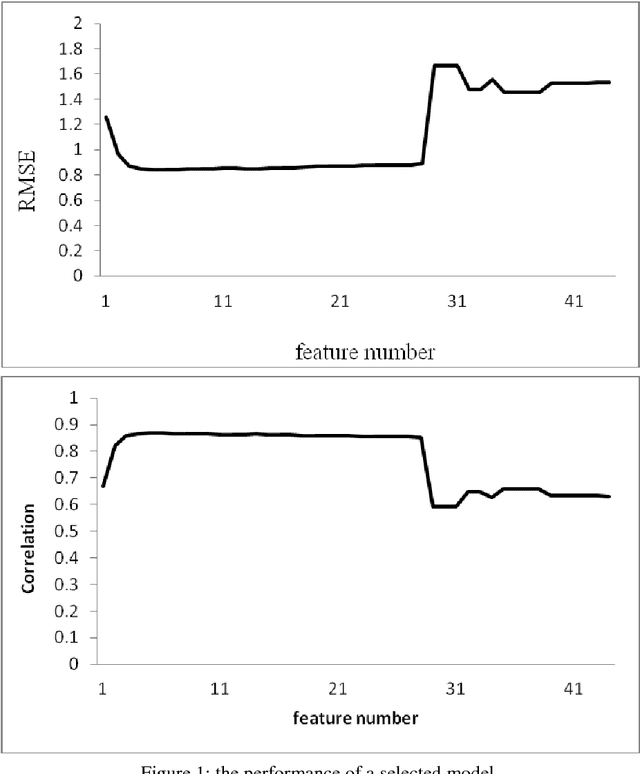

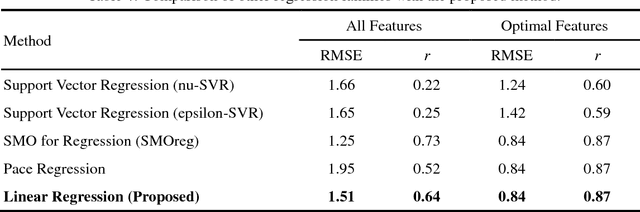
In recent years, the number of people studying English as a second language (ESL) has surpassed the number of native speakers. Recent work have demonstrated the success of providing personalized content based on reading difficulty, such as information retrieval and summarization. However, almost all prior studies of reading difficulty are designed for native speakers, rather than non-native readers. In this study, we investigate various features for ESL readers, by conducting a linear regression to estimate the reading level of English language sources. This estimation is based not only on the complexity of lexical and syntactic features, but also several novel concepts, including the age of word and grammar acquisition from several sources, word sense from WordNet, and the implicit relation between sentences. By employing Bayesian Information Criterion (BIC) to select the optimal model, we find that the combination of the number of words, the age of word acquisition and the height of the parsing tree generate better results than alternative competing models. Thus, our results show that proposed second language reading difficulty estimation outperforms other first language reading difficulty estimations.