 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqGRL: Suppressing Low-Frequency Bias and Mining High-Frequency Knowledge for Cross-Domain Few-Shot Learning
Nov 10, 2025Cross-domain few-shot learning (CD-FSL) aims to recognize novel classes with only a few labeled examples under significant domain shifts. While recent approaches leverage a limited amount of labeled target-domain data to improve performance, the severe imbalance between abundant source data and scarce target data remains a critical challenge for effective representation learning. We present the first frequency-space perspective to analyze this issue and identify two key challenges: (1) models are easily biased toward source-specific knowledge encoded in the low-frequency components of source data, and (2) the sparsity of target data hinders the learning of high-frequency, domain-generalizable features. To address these challenges, we propose \textbf{FreqGRL}, a novel CD-FSL framework that mitigates the impact of data imbalance in the frequency space. Specifically, we introduce a Low-Frequency Replacement (LFR) module that substitutes the low-frequency components of source tasks with those from the target domain to create new source tasks that better align with target characteristics, thus reducing source-specific biases and promoting generalizable representation learning. We further design a High-Frequency Enhancement (HFE) module that filters out low-frequency components and performs learning directly on high-frequency features in the frequency space to improve cross-domain generalization. Additionally, a Global Frequency Filter (GFF) is incorporated to suppress noisy or irrelevant frequencies and emphasize informative ones, mitigating overfitting risks under limited target supervision. Extensive experiments on five standard CD-FSL benchmarks demonstrate that our frequency-guided framework achieves state-of-the-art performance.
Understanding the Overfitting of the Episodic Meta-training
Jul 07, 2023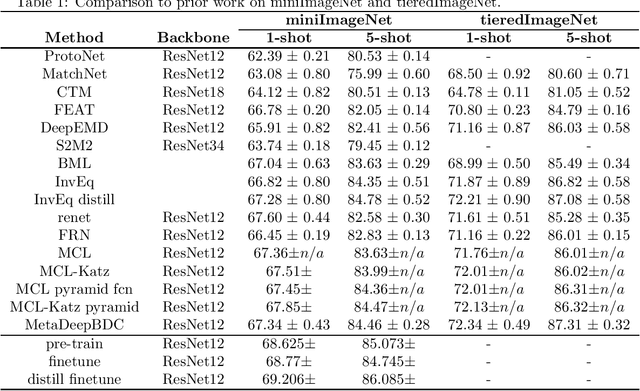
Despite the success of two-stage few-shot classification methods, in the episodic meta-training stage, the model suffers severe overfitting. We hypothesize that it is caused by over-discrimination, i.e., the model learns to over-rely on the superficial features that fit for base class discrimination while suppressing the novel class generalization. To penalize over-discrimination, we introduce knowledge distillation techniques to keep novel generalization knowledge from the teacher model during training. Specifically, we select the teacher model as the one with the best validation accuracy during meta-training and restrict the symmetric Kullback-Leibler (SKL) divergence between the output distribution of the linear classifier of the teacher model and that of the student model. This simple approach outperforms the standard meta-training process. We further propose the Nearest Neighbor Symmetric Kullback-Leibler (NNSKL) divergence for meta-training to push the limits of knowledge distillation techniques. NNSKL takes few-shot tasks as input and penalizes the output of the nearest neighbor classifier, which possesses an impact on the relationships between query embedding and support centers. By combining SKL and NNSKL in meta-training, the model achieves even better performance and surpasses state-of-the-art results on several benchmarks.