 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVSDet: Multi-View Indoor 3D Object Detection via Efficient Plane Sweeps
Oct 28, 2024
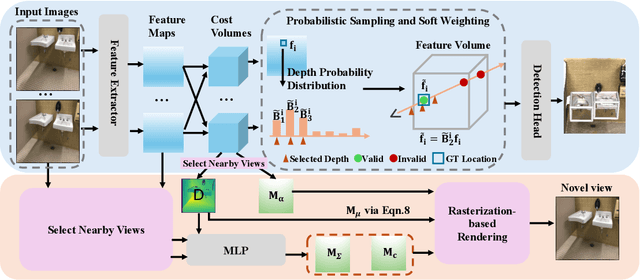


The key challenge of multi-view indoor 3D object detection is to infer accurate geometry information from images for precise 3D detection. Previous method relies on NeRF for geometry reasoning. However, the geometry extracted from NeRF is generally inaccurate, which leads to sub-optimal detection performance. In this paper, we propose MVSDet which utilizes plane sweep for geometry-aware 3D object detection. To circumvent the requirement for a large number of depth planes for accurate depth prediction, we design a probabilistic sampling and soft weighting mechanism to decide the placement of pixel features on the 3D volume. We select multiple locations that score top in the probability volume for each pixel and use their probability score to indicate the confidence. We further apply recent pixel-aligned Gaussian Splatting to regularize depth prediction and improve detection performance with little computation overhead. Extensive experiments on ScanNet and ARKitScenes datasets are conducted to show the superiority of our model. Our code is available at https://github.com/Pixie8888/MVSDet.
Rethink Cross-Modal Fusion in Weakly-Supervised Audio-Visual Video Parsing
Nov 14, 2023



Existing works on weakly-supervised audio-visual video parsing adopt hybrid attention network (HAN) as the multi-modal embedding to capture the cross-modal context. It embeds the audio and visual modalities with a shared network, where the cross-attention is performed at the input. However, such an early fusion method highly entangles the two non-fully correlated modalities and leads to sub-optimal performance in detecting single-modality events. To deal with this problem, we propose the messenger-guided mid-fusion transformer to reduce the uncorrelated cross-modal context in the fusion. The messengers condense the full cross-modal context into a compact representation to only preserve useful cross-modal information. Furthermore, due to the fact that microphones capture audio events from all directions, while cameras only record visual events within a restricted field of view, there is a more frequent occurrence of unaligned cross-modal context from audio for visual event predictions. We thus propose cross-audio prediction consistency to suppress the impact of irrelevant audio information on visual event prediction. Experiments consistently illustrate the superior performance of our framework compared to existing state-of-the-art methods.
Generalized Few-Shot Point Cloud Segmentation Via Geometric Words
Sep 20, 2023

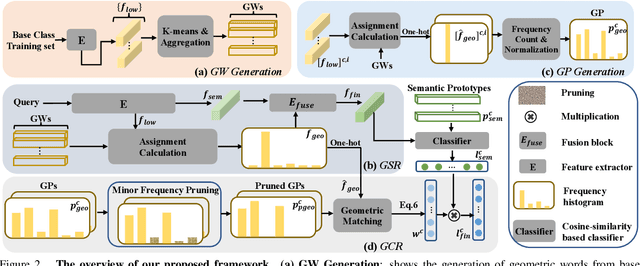

Existing fully-supervised point cloud segmentation methods suffer in the dynamic testing environment with emerging new classes. Few-shot point cloud segmentation algorithms address this problem by learning to adapt to new classes at the sacrifice of segmentation accuracy for the base classes, which severely impedes its practicality. This largely motivates us to present the first attempt at a more practical paradigm of generalized few-shot point cloud segmentation, which requires the model to generalize to new categories with only a few support point clouds and simultaneously retain the capability to segment base classes. We propose the geometric words to represent geometric components shared between the base and novel classes, and incorporate them into a novel geometric-aware semantic representation to facilitate better generalization to the new classes without forgetting the old ones. Moreover, we introduce geometric prototypes to guide the segmentation with geometric prior knowledge. Extensive experiments on S3DIS and ScanNet consistently illustrate the superior performance of our method over baseline methods. Our code is available at: https://github.com/Pixie8888/GFS-3DSeg_GWs.
Towards Robust Few-shot Point Cloud Semantic Segmentation
Sep 20, 2023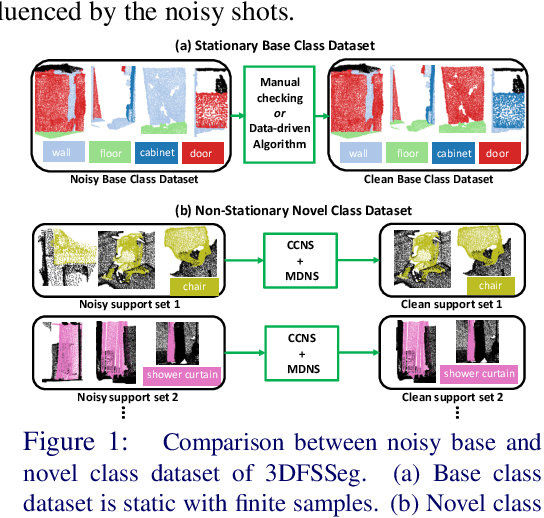
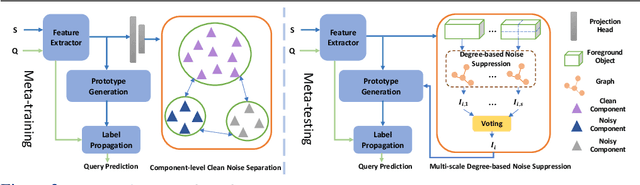

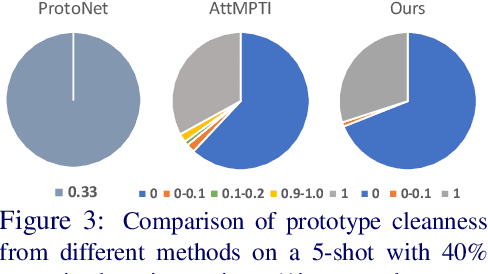
Few-shot point cloud semantic segmentation aims to train a model to quickly adapt to new unseen classes with only a handful of support set samples. However, the noise-free assumption in the support set can be easily violated in many practical real-world settings. In this paper, we focus on improving the robustness of few-shot point cloud segmentation under the detrimental influence of noisy support sets during testing time. To this end, we first propose a Component-level Clean Noise Separation (CCNS) representation learning to learn discriminative feature representations that separates the clean samples of the target classes from the noisy samples. Leveraging the well separated clean and noisy support samples from our CCNS, we further propose a Multi-scale Degree-based Noise Suppression (MDNS) scheme to remove the noisy shots from the support set. We conduct extensive experiments on various noise settings on two benchmark datasets. Our results show that the combination of CCNS and MDNS significantly improves the performance. Our code is available at https://github.com/Pixie8888/R3DFSSeg.
Motion and Context-Aware Audio-Visual Conditioned Video Prediction
Dec 09, 2022Existing state-of-the-art method for audio-visual conditioned video prediction uses the latent codes of the audio-visual frames from a multimodal stochastic network and a frame encoder to predict the next visual frame. However, a direct inference of per-pixel intensity for the next visual frame from the latent codes is extremely challenging because of the high-dimensional image space. To this end, we propose to decouple the audio-visual conditioned video prediction into motion and appearance modeling. The first part is the multimodal motion estimation module that learns motion information as optical flow from the given audio-visual clip. The second part is the context-aware refinement module that uses the predicted optical flow to warp the current visual frame into the next visual frame and refines it base on the given audio-visual context. Experimental results show that our method achieves competitive results on existing benchmarks.