 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDividing Deep Learning Model for Continuous Anomaly Detection of Inconsistent ICT Systems
Mar 24, 2020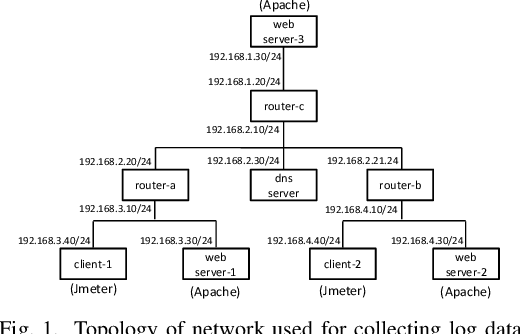



Health monitoring is important for maintaining reliable information and communications technology (ICT) systems. Anomaly detection methods based on machine learning, which train a model for describing "normality" are promising for monitoring the state of ICT systems. However, these methods cannot be used when the type of monitored log data changes from that of training data due to the replacement of certain equipment. Therefore, such methods may dismiss an anomaly that appears when log data changes. To solve this problem, we propose an ICT-systems-monitoring method with deep learning models divided based on the correlation of log data. We also propose an algorithm for extracting the correlations of log data from a deep learning model and separating log data based on the correlation. When some of the log data changes, our method can continue health monitoring with the divided models which are not affected by changes in the log data. We present the results from experiments involving benchmark data and real log data, which indicate that our method using divided models does not decrease anomaly detection accuracy and a model for anomaly detection can be divided to continue monitoring a network state even if some the log data change.
Anomaly Detection and Interpretation using Multimodal Autoencoder and Sparse Optimization
Dec 18, 2018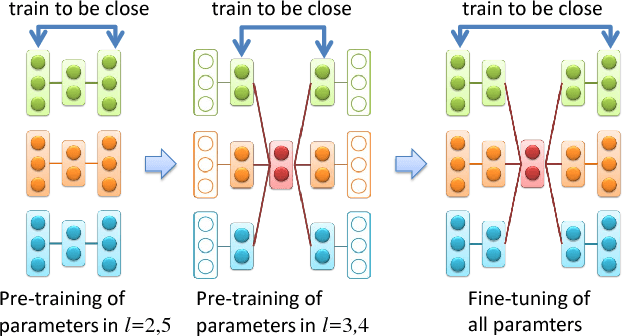
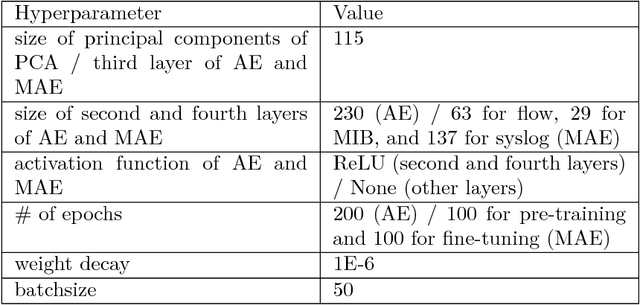
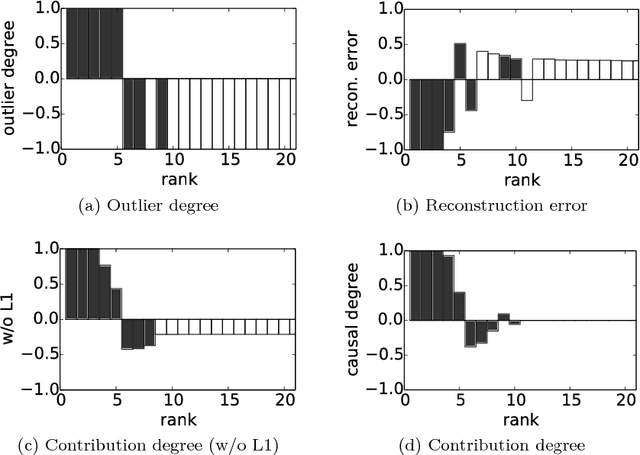
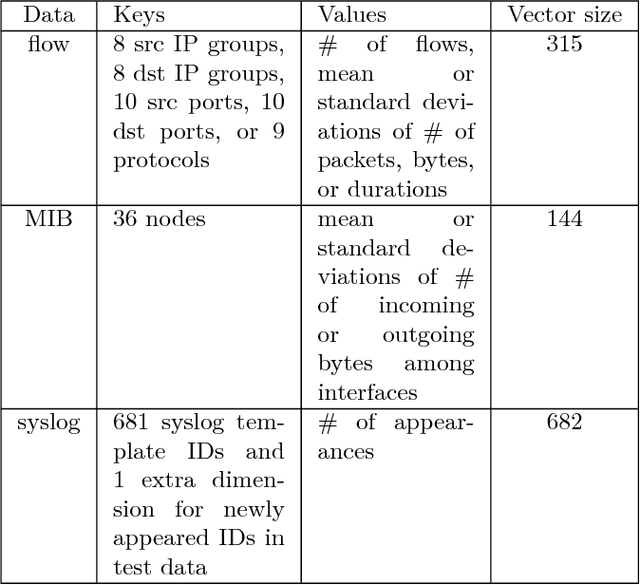
Automated anomaly detection is essential for managing information and communications technology (ICT) systems to maintain reliable services with minimum burden on operators. For detecting varying and continually emerging anomalies as differences from normal states, learning normal relationships inherent among cross-domain data monitored from ICT systems is essential. Deep-learning-based anomaly detection using an autoencoder (AE) is therefore promising for such complicated learning; however, its interpretation is still problematic. Since the dimensions of the input data contributing to the detected anomaly are not directly indicated in an AE, they are not suitable for localizing anomalies in large ICT systems composed of a huge amount of equipment. We propose an algorithm using sparse optimization for estimating contributing dimensions to anomalies detected with AEs. We also propose a multimodal AE (MAE) for effectively learning the relationships among cross-domain data, which can induce nonlinearity and differences in learnability among data types. We evaluated our algorithms with several datasets including real measured data in comparison with conventional algorithms and confirmed the superiority of our estimation algorithm in specifying contributing dimensions of anomalous data and our MAE in detecting anomalies in cross-domain data.
Estimation of Dimensions Contributing to Detected Anomalies with Variational Autoencoders
Nov 12, 2018
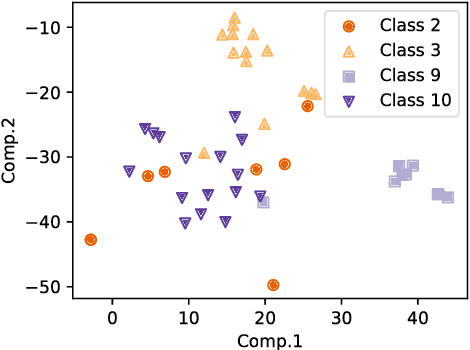

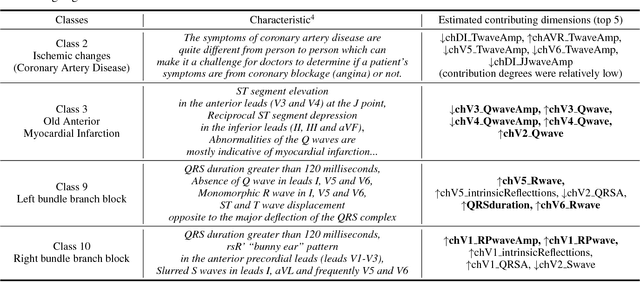
Anomaly detection using dimensionality reduction has been an essential technique for monitoring multidimensional data. Although deep learning-based methods have been well studied for their remarkable detection performance, their interpretability is still a problem. In this paper, we propose a novel algorithm for estimating the dimensions contributing to the detected anomalies by using variational autoencoders (VAEs). Our algorithm is based on an approximative probabilistic model that considers the existence of anomalies in the data, and by maximizing the log-likelihood, we estimate which dimensions contribute to determining data as an anomaly. The experiments results with benchmark datasets show that our algorithm extracts the contributing dimensions more accurately than baseline methods.