 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial-Intelligence Generated Code Considered Harmful: A Road Map for Secure and High-Quality Code Generation
Sep 27, 2024

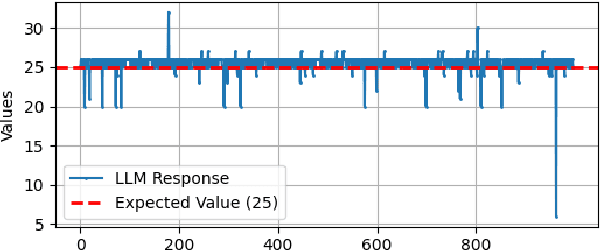
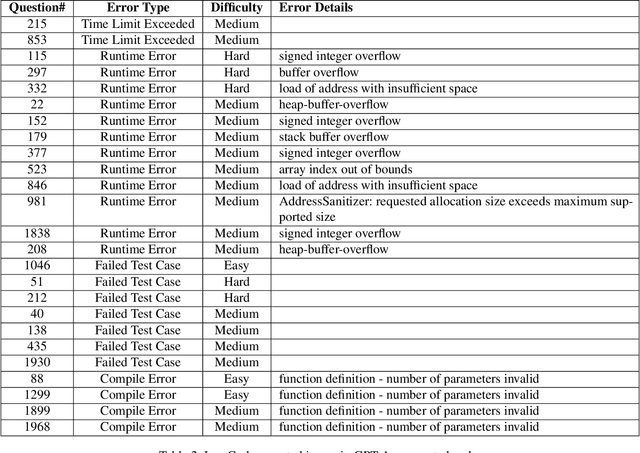
Generating code via a LLM (rather than writing code from scratch), has exploded in popularity. However, the security implications of LLM-generated code are still unknown. We performed a study that compared the security and quality of human-written code with that of LLM-generated code, for a wide range of programming tasks, including data structures, algorithms, cryptographic routines, and LeetCode questions. To assess code security we used unit testing, fuzzing, and static analysis. For code quality, we focused on complexity and size. We found that LLM can generate incorrect code that fails to implement the required functionality, especially for more complicated tasks; such errors can be subtle. For example, for the cryptographic algorithm SHA1, LLM generated an incorrect implementation that nevertheless compiles. In cases where its functionality was correct, we found that LLM-generated code is less secure, primarily due to the lack of defensive programming constructs, which invites a host of security issues such as buffer overflows or integer overflows. Fuzzing has revealed that LLM-generated code is more prone to hangs and crashes than human-written code. Quality-wise, we found that LLM generates bare-bones code that lacks defensive programming constructs, and is typically more complex (per line of code) compared to human-written code. Next, we constructed a feedback loop that asked the LLM to re-generate the code and eliminate the found issues (e.g., malloc overflow, array index out of bounds, null dereferences). We found that the LLM fails to eliminate such issues consistently: while succeeding in some cases, we found instances where the re-generated, supposedly more secure code, contains new issues; we also found that upon prompting, LLM can introduce issues in files that were issues-free before prompting.
Deep Phenotyping of Non-Alcoholic Fatty Liver Disease Patients with Genetic Factors for Insights into the Complex Disease
Nov 13, 2023


Non-alcoholic fatty liver disease (NAFLD) is a prevalent chronic liver disorder characterized by the excessive accumulation of fat in the liver in individuals who do not consume significant amounts of alcohol, including risk factors like obesity, insulin resistance, type 2 diabetes, etc. We aim to identify subgroups of NAFLD patients based on demographic, clinical, and genetic characteristics for precision medicine. The genomic and phenotypic data (3,408 cases and 4,739 controls) for this study were gathered from participants in Mayo Clinic Tapestry Study (IRB#19-000001) and their electric health records, including their demographic, clinical, and comorbidity data, and the genotype information through whole exome sequencing performed at Helix using the Exome+$^\circledR$ Assay according to standard procedure (www$.$helix$.$com). Factors highly relevant to NAFLD were determined by the chi-square test and stepwise backward-forward regression model. Latent class analysis (LCA) was performed on NAFLD cases using significant indicator variables to identify subgroups. The optimal clustering revealed 5 latent subgroups from 2,013 NAFLD patients (mean age 60.6 years and 62.1% women), while a polygenic risk score based on 6 single-nucleotide polymorphism (SNP) variants and disease outcomes were used to analyze the subgroups. The groups are characterized by metabolic syndrome, obesity, different comorbidities, psychoneurological factors, and genetic factors. Odds ratios were utilized to compare the risk of complex diseases, such as fibrosis, cirrhosis, and hepatocellular carcinoma (HCC), as well as liver failure between the clusters. Cluster 2 has a significantly higher complex disease outcome compared to other clusters. Keywords: Fatty liver disease; Polygenic risk score; Precision medicine; Deep phenotyping; NAFLD comorbidities; Latent class analysis.