 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial-Intelligence Generated Code Considered Harmful: A Road Map for Secure and High-Quality Code Generation
Sep 27, 2024

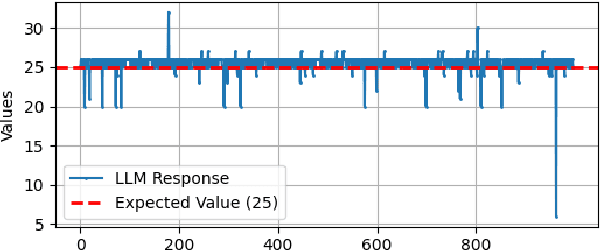
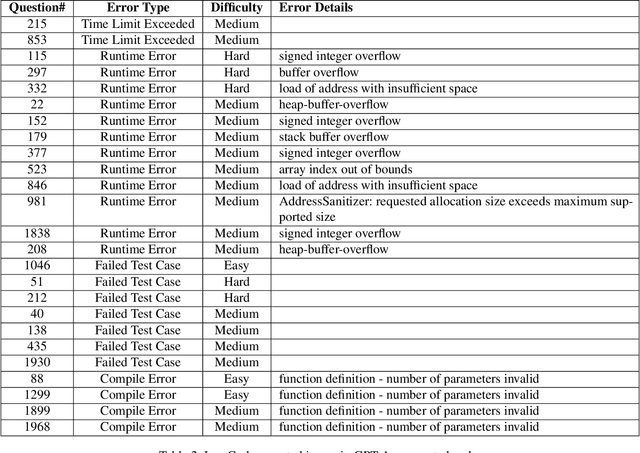
Generating code via a LLM (rather than writing code from scratch), has exploded in popularity. However, the security implications of LLM-generated code are still unknown. We performed a study that compared the security and quality of human-written code with that of LLM-generated code, for a wide range of programming tasks, including data structures, algorithms, cryptographic routines, and LeetCode questions. To assess code security we used unit testing, fuzzing, and static analysis. For code quality, we focused on complexity and size. We found that LLM can generate incorrect code that fails to implement the required functionality, especially for more complicated tasks; such errors can be subtle. For example, for the cryptographic algorithm SHA1, LLM generated an incorrect implementation that nevertheless compiles. In cases where its functionality was correct, we found that LLM-generated code is less secure, primarily due to the lack of defensive programming constructs, which invites a host of security issues such as buffer overflows or integer overflows. Fuzzing has revealed that LLM-generated code is more prone to hangs and crashes than human-written code. Quality-wise, we found that LLM generates bare-bones code that lacks defensive programming constructs, and is typically more complex (per line of code) compared to human-written code. Next, we constructed a feedback loop that asked the LLM to re-generate the code and eliminate the found issues (e.g., malloc overflow, array index out of bounds, null dereferences). We found that the LLM fails to eliminate such issues consistently: while succeeding in some cases, we found instances where the re-generated, supposedly more secure code, contains new issues; we also found that upon prompting, LLM can introduce issues in files that were issues-free before prompting.
Casper: Prompt Sanitization for Protecting User Privacy in Web-Based Large Language Models
Aug 13, 2024



Web-based Large Language Model (LLM) services have been widely adopted and have become an integral part of our Internet experience. Third-party plugins enhance the functionalities of LLM by enabling access to real-world data and services. However, the privacy consequences associated with these services and their third-party plugins are not well understood. Sensitive prompt data are stored, processed, and shared by cloud-based LLM providers and third-party plugins. In this paper, we propose Casper, a prompt sanitization technique that aims to protect user privacy by detecting and removing sensitive information from user inputs before sending them to LLM services. Casper runs entirely on the user's device as a browser extension and does not require any changes to the online LLM services. At the core of Casper is a three-layered sanitization mechanism consisting of a rule-based filter, a Machine Learning (ML)-based named entity recognizer, and a browser-based local LLM topic identifier. We evaluate Casper on a dataset of 4000 synthesized prompts and show that it can effectively filter out Personal Identifiable Information (PII) and privacy-sensitive topics with high accuracy, at 98.5% and 89.9%, respectively.