 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMIL: Hierarchical Aggregation-Based Multi-Instance Learning for Microscopy Image Classification
Mar 17, 2021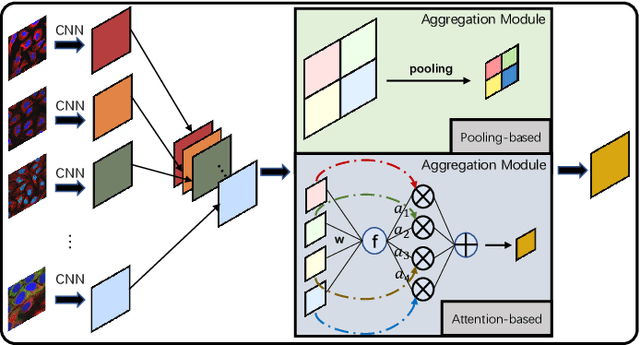
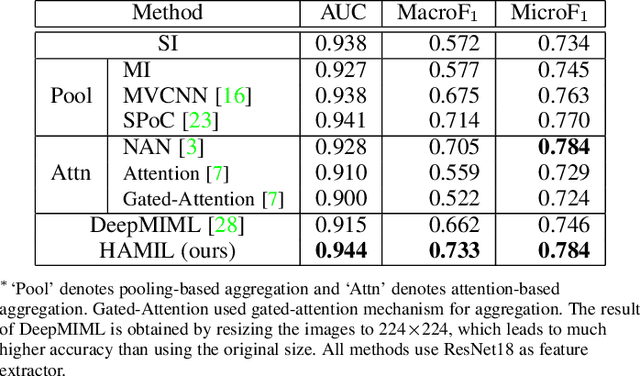
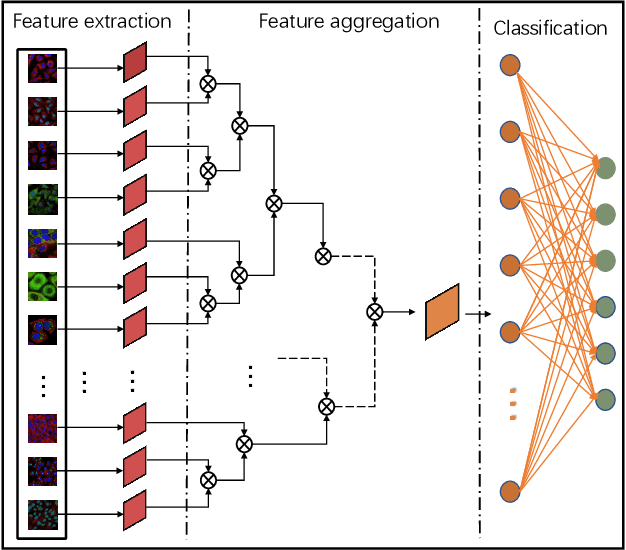
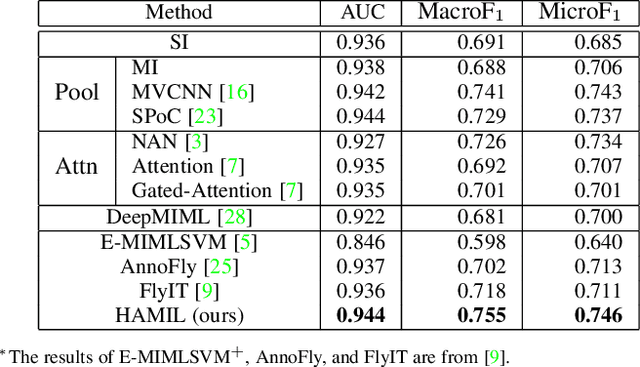
Multi-instance learning is common for computer vision tasks, especially in biomedical image processing. Traditional methods for multi-instance learning focus on designing feature aggregation methods and multi-instance classifiers, where the aggregation operation is performed either in feature extraction or learning phase. As deep neural networks (DNNs) achieve great success in image processing via automatic feature learning, certain feature aggregation mechanisms need to be incorporated into common DNN architecture for multi-instance learning. Moreover, flexibility and reliability are crucial considerations to deal with varying quality and number of instances. In this study, we propose a hierarchical aggregation network for multi-instance learning, called HAMIL. The hierarchical aggregation protocol enables feature fusion in a defined order, and the simple convolutional aggregation units lead to an efficient and flexible architecture. We assess the model performance on two microscopy image classification tasks, namely protein subcellular localization using immunofluorescence images and gene annotation using spatial gene expression images. The experimental results show that HAMIL outperforms the state-of-the-art feature aggregation methods and the existing models for addressing these two tasks. The visualization analyses also demonstrate the ability of HAMIL to focus on high-quality instances.
AAG: Self-Supervised Representation Learning by Auxiliary Augmentation with GNT-Xent Loss
Sep 17, 2020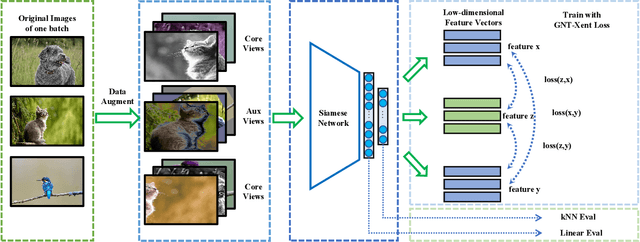
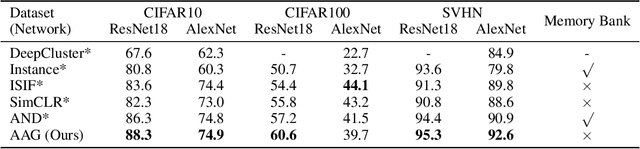


Self-supervised representation learning is an emerging research topic for its powerful capacity in learning with unlabeled data. As a mainstream self-supervised learning method, augmentation-based contrastive learning has achieved great success in various computer vision tasks that lack manual annotations. Despite current progress, the existing methods are often limited by extra cost on memory or storage, and their performance still has large room for improvement. Here we present a self-supervised representation learning method, namely AAG, which is featured by an auxiliary augmentation strategy and GNT-Xent loss. The auxiliary augmentation is able to promote the performance of contrastive learning by increasing the diversity of images. The proposed GNT-Xent loss enables a steady and fast training process and yields competitive accuracy. Experiment results demonstrate the superiority of AAG to previous state-of-the-art methods on CIFAR10, CIFAR100, and SVHN. Especially, AAG achieves 94.5% top-1 accuracy on CIFAR10 with batch size 64, which is 0.5% higher than the best result of SimCLR with batch size 1024.