 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking public attitudes toward ChatGPT on Twitter using sentiment analysis and topic modeling
Jun 22, 2023ChatGPT sets a new record with the fastest-growing user base, as a chatbot powered by a large language model (LLM). While it demonstrates state-of-the-art capabilities in a variety of language-generating tasks, it also raises widespread public concerns regarding its societal impact. In this paper, we utilize natural language processing approaches to investigate the public attitudes towards ChatGPT by applying sentiment analysis and topic modeling techniques to Twitter data. Our result shows that the overall sentiment is largely neutral to positive, which also holds true across different occupation groups. Among a wide range of topics mentioned in tweets, the most popular topics are Artificial Intelligence, Search Engines, Education, Writing, and Question Answering.
A Simple Baseline for Adversarial Domain Adaptation-based Unsupervised Flood Forecasting
Jun 16, 2022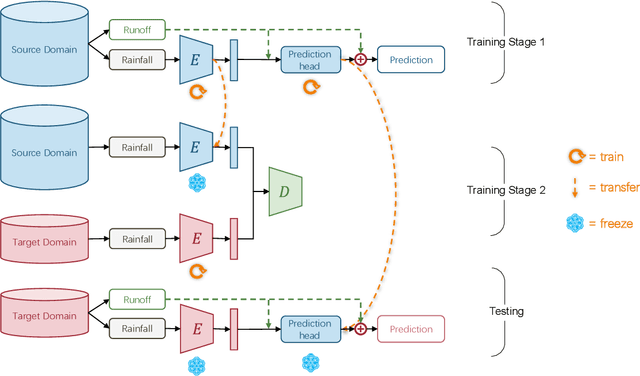
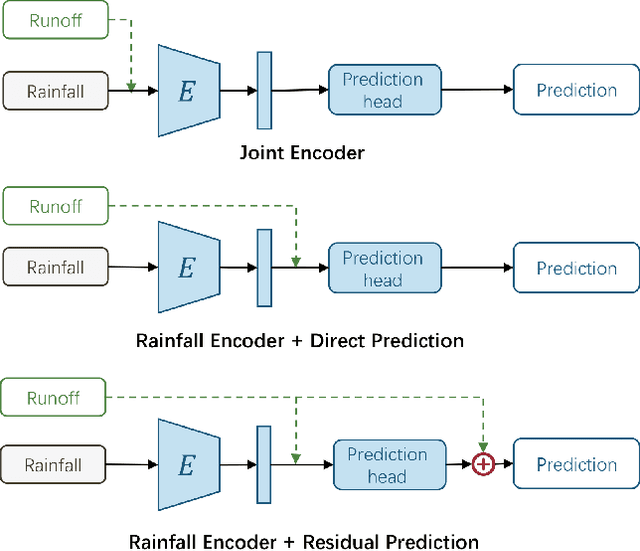
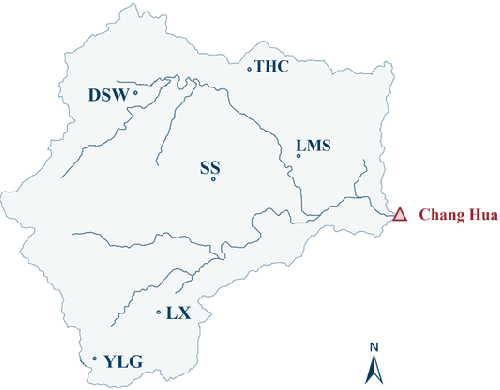
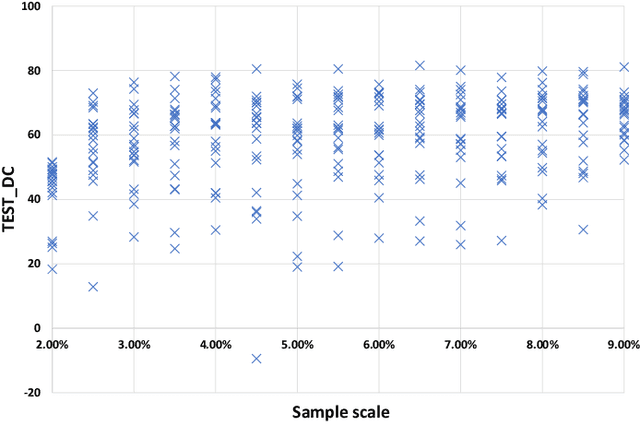
Flood disasters cause enormous social and economic losses. However, both traditional physical models and learning-based flood forecasting models require massive historical flood data to train the model parameters. When come to some new site that does not have sufficient historical data, the model performance will drop dramatically due to overfitting. This technical report presents a Flood Domain Adaptation Network (FloodDAN), a baseline of applying Unsupervised Domain Adaptation (UDA) to the flood forecasting problem. Specifically, training of FloodDAN includes two stages: in the first stage, we train a rainfall encoder and a prediction head to learn general transferable hydrological knowledge on large-scale source domain data; in the second stage, we transfer the knowledge in the pretrained encoder into the rainfall encoder of target domain through adversarial domain alignment. During inference, we utilize the target domain rainfall encoder trained in the second stage and the prediction head trained in the first stage to get flood forecasting predictions. Experimental results on Tunxi and Changhua flood dataset show that FloodDAN can perform flood forecasting effectively with zero target domain supervision. The performance of the FloodDAN is on par with supervised models that uses 450-500 hours of supervision.