 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAVBench and UAVIT-1M: Benchmarking and Enhancing MLLMs for Low-Altitude UAV Vision-Language Understanding
Mar 15, 2026Multimodal Large Language Models (MLLMs) have made significant strides in natural images and satellite remote sensing images. However, understanding low-altitude drone scenarios remains a challenge. Existing datasets primarily focus on a few specific low-altitude visual tasks, which cannot fully assess the ability of MLLMs in real-world low-altitude UAV applications. Therefore, we introduce UAVBench, a comprehensive benchmark, and UAVIT-1M, a large-scale instruction tuning dataset, designed to evaluate and improve MLLMs' abilities in low-altitude vision-language tasks. UAVBench comprises 43 test units and 966k high-quality data samples across 10 tasks at the image-level and region-level. UAVIT-1M consists of approximately 1.24 million diverse instructions, covering 789k multi-scene images and about 2,000 types of spatial resolutions with 11 distinct tasks. UAVBench and UAVIT-1M feature pure real-world visual images and rich weather conditions, and involve manual verification to ensure high quality. Our in-depth analysis of 11 state-of-the-art MLLMs using UAVBench reveals that open-source MLLMs cannot generate accurate conversations about low-altitude visual content, lagging behind closed-source MLLMs. Extensive experiments demonstrate that fine-tuning open-source MLLMs on UAVIT-1M significantly addresses this gap. Our contributions pave the way for bridging the gap between current MLLMs and low-altitude UAV real-world application demands. (Project page: https://UAVBench.github.io/)
ShipTraj-R1: Reinforcing Ship Trajectory Prediction in Large Language Models via Group Relative Policy Optimization
Mar 03, 2026Recent advancements in reinforcement fine-tuning have significantly improved the reasoning ability of large language models (LLMs). In particular, methods such as group relative policy optimization (GRPO) have demonstrated strong capabilities across various fields. However, applying LLMs to ship trajectory prediction remains largely unexplored. In this paper, we propose ShipTraj-R1, a novel LLM-based framework that reformulates ship trajectory prediction as a text-to-text generation problem. (1) We design a dynamic prompt containing trajectory information about conflicting ships to guide the model to achieve adaptive chain-of-thought (CoT) reasoning. (2) We introduce a comprehensive rule-based reward mechanism to incentivize the reasoning format and prediction accuracy of the model. (3) Our ShipTraj-R1 is reinforced through the GRPO mechanism guided by domain-specific prompts and rewards, and utilizes the Qwen3 as the model backbone. Extensive experimental results on two complex and real-world maritime datasets show that the proposed ShipTraj-R1 achieves the least error compared with state-of-the-art deep learning and LLM-based baselines.
From Atoms to Trees: Building a Structured Feature Forest with Hierarchical Sparse Autoencoders
Feb 12, 2026Sparse autoencoders (SAEs) have proven effective for extracting monosemantic features from large language models (LLMs), yet these features are typically identified in isolation. However, broad evidence suggests that LLMs capture the intrinsic structure of natural language, where the phenomenon of "feature splitting" in particular indicates that such structure is hierarchical. To capture this, we propose the Hierarchical Sparse Autoencoder (HSAE), which jointly learns a series of SAEs and the parent-child relationships between their features. HSAE strengthens the alignment between parent and child features through two novel mechanisms: a structural constraint loss and a random feature perturbation mechanism. Extensive experiments across various LLMs and layers demonstrate that HSAE consistently recovers semantically meaningful hierarchies, supported by both qualitative case studies and rigorous quantitative metrics. At the same time, HSAE preserves the reconstruction fidelity and interpretability of standard SAEs across different dictionary sizes. Our work provides a powerful, scalable tool for discovering and analyzing the multi-scale conceptual structures embedded in LLM representations.
SkyEyeGPT: Unifying Remote Sensing Vision-Language Tasks via Instruction Tuning with Large Language Model
Jan 18, 2024



Large language models (LLMs) have recently been extended to the vision-language realm, obtaining impressive general multi-modal capabilities. However, the exploration of multi-modal large language models (MLLMs) for remote sensing (RS) data is still in its infancy, and the performance is not satisfactory. In this work, we introduce SkyEyeGPT, a unified multi-modal large language model specifically designed for RS vision-language understanding. To this end, we meticulously curate an RS multi-modal instruction tuning dataset, including single-task and multi-task conversation instructions. After manual verification, we obtain a high-quality RS instruction-following dataset with 968k samples. Our research demonstrates that with a simple yet effective design, SkyEyeGPT works surprisingly well on considerably different tasks without the need for extra encoding modules. Specifically, after projecting RS visual features to the language domain via an alignment layer, they are fed jointly with task-specific instructions into an LLM-based RS decoder to predict answers for RS open-ended tasks. In addition, we design a two-stage tuning method to enhance instruction-following and multi-turn dialogue ability at different granularities. Experiments on 8 datasets for RS vision-language tasks demonstrate SkyEyeGPT's superiority in image-level and region-level tasks, such as captioning and visual grounding. In particular, SkyEyeGPT exhibits encouraging results compared to GPT-4V in some qualitative tests. The online demo, code, and dataset will be released in https://github.com/ZhanYang-nwpu/SkyEyeGPT.
Mono3DVG: 3D Visual Grounding in Monocular Images
Dec 13, 2023We introduce a novel task of 3D visual grounding in monocular RGB images using language descriptions with both appearance and geometry information. Specifically, we build a large-scale dataset, Mono3DRefer, which contains 3D object targets with their corresponding geometric text descriptions, generated by ChatGPT and refined manually. To foster this task, we propose Mono3DVG-TR, an end-to-end transformer-based network, which takes advantage of both the appearance and geometry information in text embeddings for multi-modal learning and 3D object localization. Depth predictor is designed to explicitly learn geometry features. The dual text-guided adapter is proposed to refine multiscale visual and geometry features of the referred object. Based on depth-text-visual stacking attention, the decoder fuses object-level geometric cues and visual appearance into a learnable query. Comprehensive benchmarks and some insightful analyses are provided for Mono3DVG. Extensive comparisons and ablation studies show that our method significantly outperforms all baselines. The dataset and code will be publicly available at: https://github.com/ZhanYang-nwpu/Mono3DVG.
Parameter-Efficient Transfer Learning for Remote Sensing Image-Text Retrieval
Aug 24, 2023

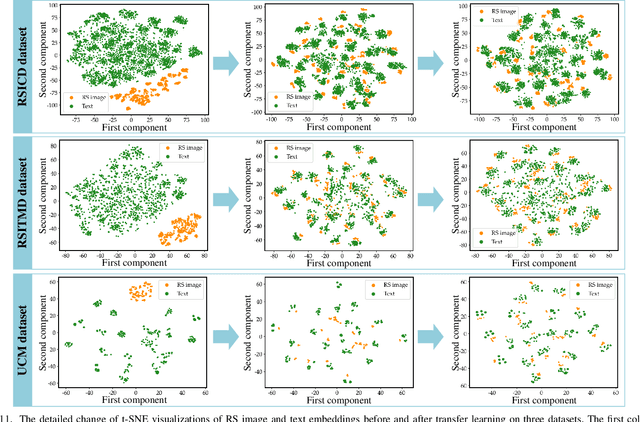

Vision-and-language pre-training (VLP) models have experienced a surge in popularity recently. By fine-tuning them on specific datasets, significant performance improvements have been observed in various tasks. However, full fine-tuning of VLP models not only consumes a significant amount of computational resources but also has a significant environmental impact. Moreover, as remote sensing (RS) data is constantly being updated, full fine-tuning may not be practical for real-world applications. To address this issue, in this work, we investigate the parameter-efficient transfer learning (PETL) method to effectively and efficiently transfer visual-language knowledge from the natural domain to the RS domain on the image-text retrieval task. To this end, we make the following contributions. 1) We construct a novel and sophisticated PETL framework for the RS image-text retrieval (RSITR) task, which includes the pretrained CLIP model, a multimodal remote sensing adapter, and a hybrid multi-modal contrastive (HMMC) learning objective; 2) To deal with the problem of high intra-modal similarity in RS data, we design a simple yet effective HMMC loss; 3) We provide comprehensive empirical studies for PETL-based RS image-text retrieval. Our results demonstrate that the proposed method is promising and of great potential for practical applications. 4) We benchmark extensive state-of-the-art PETL methods on the RSITR task. Our proposed model only contains 0.16M training parameters, which can achieve a parameter reduction of 98.9% compared to full fine-tuning, resulting in substantial savings in training costs. Our retrieval performance exceeds traditional methods by 7-13% and achieves comparable or better performance than full fine-tuning. This work can provide new ideas and useful insights for RS vision-language tasks.
RSVG: Exploring Data and Models for Visual Grounding on Remote Sensing Data
Oct 23, 2022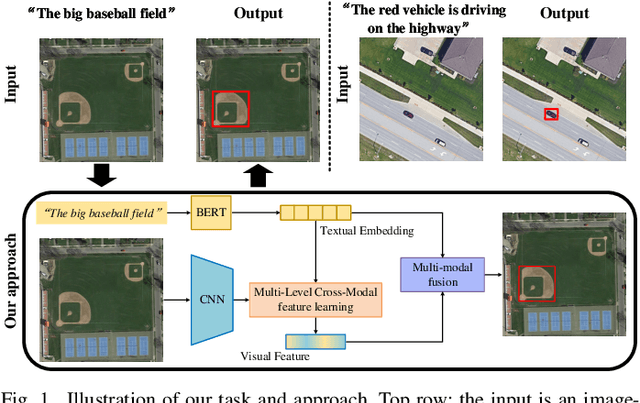
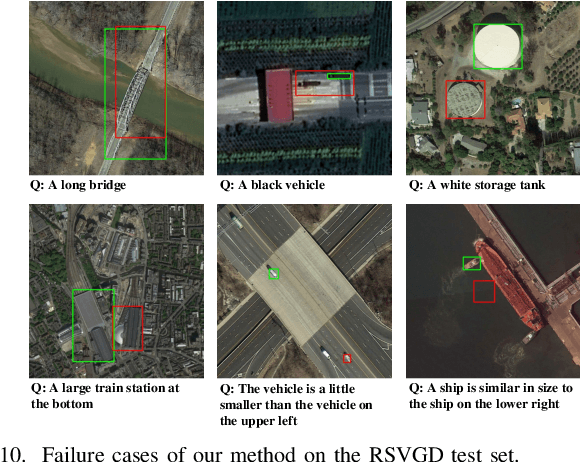

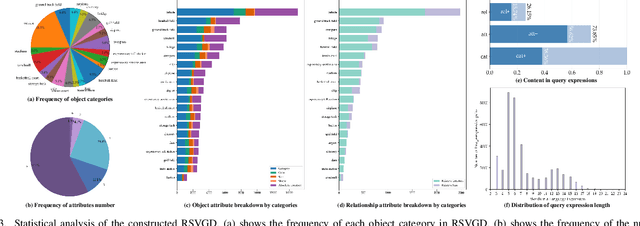
In this paper, we introduce the task of visual grounding for remote sensing data (RSVG). RSVG aims to localize the referred objects in remote sensing (RS) images with the guidance of natural language. To retrieve rich information from RS imagery using natural language, many research tasks, like RS image visual question answering, RS image captioning, and RS image-text retrieval have been investigated a lot. However, the object-level visual grounding on RS images is still under-explored. Thus, in this work, we propose to construct the dataset and explore deep learning models for the RSVG task. Specifically, our contributions can be summarized as follows. 1) We build the new large-scale benchmark dataset of RSVG, termed RSVGD, to fully advance the research of RSVG. This new dataset includes image/expression/box triplets for training and evaluating visual grounding models. 2) We benchmark extensive state-of-the-art (SOTA) natural image visual grounding methods on the constructed RSVGD dataset, and some insightful analyses are provided based on the results. 3) A novel transformer-based Multi-Level Cross-Modal feature learning (MLCM) module is proposed. Remotely-sensed images are usually with large scale variations and cluttered backgrounds. To deal with the scale-variation problem, the MLCM module takes advantage of multi-scale visual features and multi-granularity textual embeddings to learn more discriminative representations. To cope with the cluttered background problem, MLCM adaptively filters irrelevant noise and enhances salient features. In this way, our proposed model can incorporate more effective multi-level and multi-modal features to boost performance. Furthermore, this work also provides useful insights for developing better RSVG models. The dataset and code will be publicly available at https://github.com/ZhanYang-nwpu/RSVG-pytorch.